
Intro
Any-to-any multimodal models combining text, images, video, and audio are advancing AI, but their complex architectures, mixing autoregressive LLMs and diffusion transformers, make efficient serving very difficult. Current systems like OpenAI’s ChatGPT (text) and Sora (video) run as separate engines, lacking unified any-to-any pipelines. vLLM-Omni solves just that with a fully disaggregated serving system designed for interconnected, multi-component models.
I. What is vLLM-Omni?

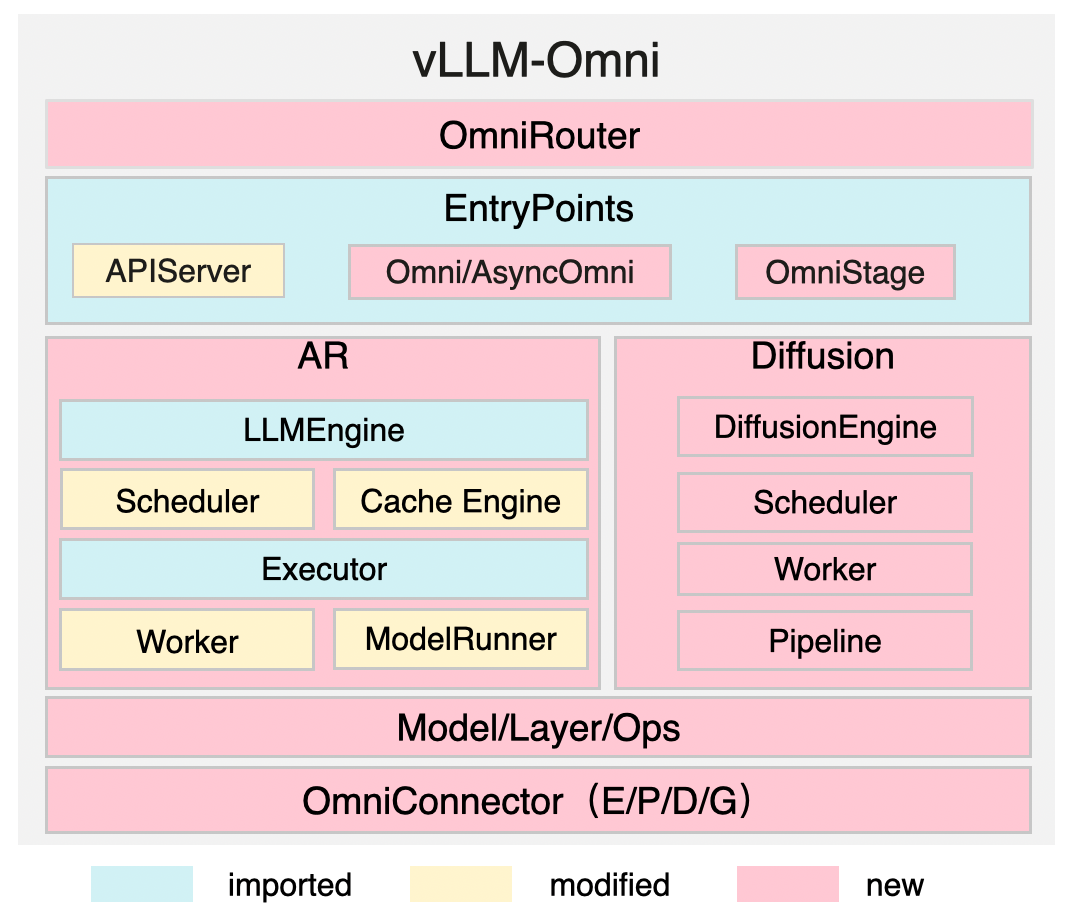
vLLM-Omni is a purposeful extension of vLLM core that adds multimodal and non-autoregressive model support while preserving full compatibility with vLLM’s scheduling and KV cache optimizations. That means anything from Image generation text to speech even video generation can be done through this new serving engine flavor.
📄 Slides (PDF) · vllm-omni_multimodal_inference_Cloudthrill.pdf
Design intent
The secret sauce is to serve both text generation that relies on Autoregressive(AR) models and Multi-Modal generation using Diffusion(Dit) model. All in a heterogenous pipeline (multimedia input and output).

Two In One Architecture: AR vs. DiT
| Feature | Autoregressive (AR) | Diffusion Transformer (DiT) |
|---|---|---|
| Core Examples | Qwen3-Omni, Qwen2.5-Omni | Wan 2.2, FLUX.2, BAGEL |
| Mechanism | Token-by-token (Thinker/Talker) | Step-based Denoising (MoE Experts) |
| Bottleneck | Decode: Memory bound (KV Cache) | Compute bound (High-throughput generation) |
| NPU Efficiency | High (Memory-efficient decoding) | Ultra-High (Dedicated Matrix Engines) |
How does it extend vLLM


- Intercepting the CLI
--omniSwitch- CLI checks for
--omniflag; if absent, it calls vLLM’s main directly . - If present, it loads vLLM-Omni’s serve module and dispatches accordingly . If not the CLI behave like vLLM
- CLI checks for
- Runtime patching of vLLM symbols at import
- Replaces vLLM classes with Omni equivalents at import
- Ensures all vLLM internals use Omni-enhanced classes
- Inheriting key vLLM classes to add omni-specific capabilities.
- Adds omni-specific configuration & connectors including an LLMEngine like vLLM
- AsyncOmniLLM extends vLLM’s AsyncLLM for async, per-stage execution
- OmniEngineArgs extends vLLM’s EngineArgs with omni fields like stage_id and model_stage
- Schedulers and workers also inherit from vLLM bases, e.g., OmniARScheduler extends VLLMScheduler
II. Architecture Overview 🚀
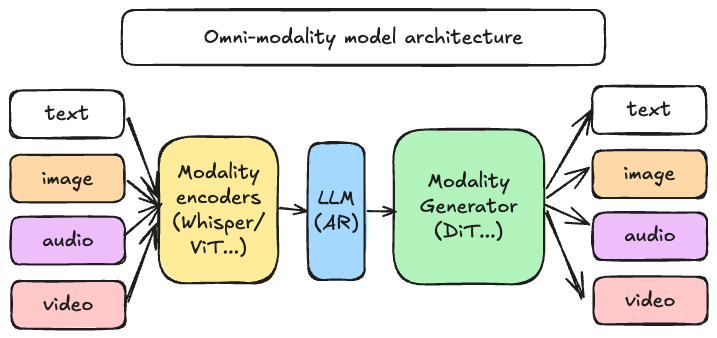
- Modality Encoders: Thinker stage that uses separate encoders for each input modality(Vision/Audio Encoders)
- LLM AR (Autoregressive Language Model): Core Language model that generates text tokens sequentially
- Modality Generator: Uses different generators depending on the output modality (txt-to-img,TTS,img-to-vid…)
Omni-Modality Serving Architecture
In this Advanced dispatching and orchestration stack for multi-modal AI workloads. AutoRegressive(AR) Module handles all text based workload like vLLM while Diffusion takes care of other modalities.
INTELLIGENCE
API LAYER
AUTOREGRESSIVE
GENERATIVE
DISAGGREGATION
DISAGGREGATION
Natively Disaggregated Serving
vLLM-Omni runs each model stage in its own process/device, connected via OmniConnector. This enables heterogeneous pipelines (AR + DiT) and dynamic resource allocation across stages

AR Vs Diffusion Module Design
Below is the core architecture of each AR and Difusion modules that makes Omni-modality work under vLLm-Omni.

Omni-Modality Pipeline Stages
Thinker/Talker/Code2Wav is defined in Qwen-Omni stage configs to produce audio output via waveform decoding.
| Stage | Role & Description | Outputs / Data Flow |
|---|---|---|
|
Thinker
Understanding
|
Function
Multimodal understanding stage. Processes text, image, video, or audio inputs to generate reasoning states.
|
Flow
Generates text tokens and hidden state embeddings (e.g., layers 0 and 24) passed to the Talker stage.
|
|
Talker
Codec Logic
|
Function
Speech synthesis stage. Converts the Thinker’s text and hidden embeddings into multi-layer RVQ codec codes.
|
Flow
Produces 16 layers of RVQ codes passed downstream to the Code2Wav decoder.
|
|
Code2Wav
Waveform
|
Function
Audio decoding stage. Transforms the RVQ codes into a high-fidelity audible waveform.
|
Flow
Final 24 kHz audio waveform tensor returned as the terminal response to the client.
|
Omni-Modal Request Workflow

Diffusion models
Diffusion models use a single diffusion stage and expose image/video outputs directly, without intermediate stages
🧠Model Support
vLLM-Omni supports 20+ popular omni and diffusion model architectures(growing rapidly) including Stable Diffusion 3.5 see full list.

Supported Models Matrix (NVIDIA / AMD) includes Helios .
| Models | Architecture | Example HF Models / Identifiers |
|---|---|---|
| Qwen3-Omni | Qwen3OmniMoeForConditionalGeneration | Qwen/Qwen3-Omni-30B-A3B-Instruct |
| Qwen2.5-Omni | Qwen2_5OmniForConditionalGeneration | Qwen/Qwen2.5-Omni-7B, Qwen/Qwen2.5-Omni-3B |
| BAGEL (DiT-only) | BagelForConditionalGeneration | ByteDance-Seed/BAGEL-7B-MoT |
| Qwen-Image (2512) | QwenImagePipeline | Qwen/Qwen-Image, Qwen/Qwen-Image-2512 |
| Qwen-Image-Edit (2509) | QwenImageEditPlusPipeline | Qwen/Qwen-Image-Edit-2509 |
| Wan2.2 (T2V / TI2V) | WanPipeline | Wan-AI/Wan2.2-T2V-A14B-Diffusers, Wan2.2-TI2V-5B |
| Wan2.2-I2V | WanImageToVideoPipeline | Wan-AI/Wan2.2-I2V-A14B-Diffusers |
| FLUX.2-klein | Flux2KleinPipeline | black-forest-labs/FLUX.2-klein-9B |
| Stable-Audio-Open | StableAudioPipeline | stabilityai/stable-audio-open-1.0 |
| Qwen3-TTS (12Hz) | Qwen3TTSForConditionalGeneration | Qwen3-TTS-12Hz-1.7B-VoiceDesign, Base, CustomVoice |
| Ovis-Image | OvisImagePipeline | OvisAI/Ovis-Image |
| LongCat-Image | LongcatImagePipeline | meituan-longcat/LongCat-Image |
List of Supported Models for NPU (i.e Huawei Ascend Atlas)
| Models | Architecture | Example HF Models NPU compatible |
|---|---|---|
| Qwen3-Omni | Qwen3OmniMoeForConditionalGeneration | Qwen/Qwen3-Omni-30B-A3B-Instruct |
| Qwen2.5-Omni | Qwen2_5OmniForConditionalGeneration | Qwen/Qwen2.5-Omni-7B, Qwen2.5-Omni-3B |
| Qwen-Image / 2512 | QwenImagePipeline | Qwen/Qwen-Image, Qwen/Qwen-Image-2512 |
| Qwen-Image-Edit (2509/2511) | QwenImageEditPlusPipeline | Qwen/Qwen-Image-Edit-2511, Qwen-Image-Edit-2509 |
| Z-Image | ZImagePipeline | Tongyi-MAI/Z-Image-Turbo |
| FLUX.2-klein | Flux2KleinPipeline | black-forest-labs/FLUX.2-klein-9B |
| Qwen3-TTS-12Hz | Qwen3TTSForConditionalGeneration | Qwen3-TTS-12Hz-1.7B-VoiceDesign, Base, CustomVoice |
| LongCat-Image | LongcatImagePipeline | meituan-longcat/LongCat-Image |
⚡Diffusion stage acceleration

- TeaCache: Caches transformer computations when consecutive timesteps are similar speeding-up by ~1.5x–2.0x
- Cache-DiT: speeds up diffusion transformers via DBCache (dual block), TaylorSeer (forecasting), & SCM
- Ulysses-SP: Splits seq dimensions & uses all-to-all communication so attention heads can be processed in parallel
- Ring-Attention: Splits the sequence dimension and circulates KV blocks in a ring topology to accumulate attention & shard sequences
- Other: Parallelism, Quantization, Fused Ops, Timestep distillation
Interface design
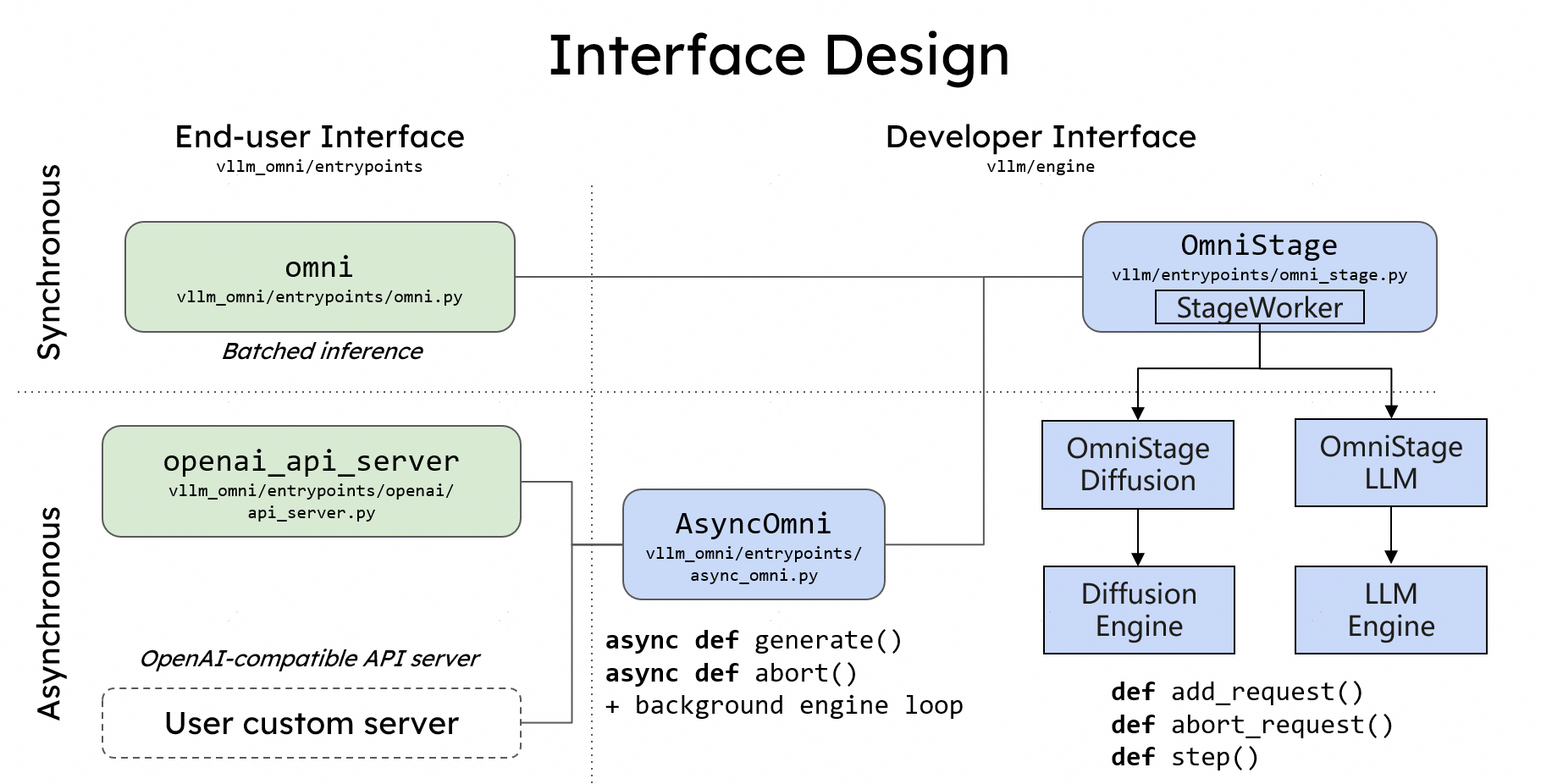
- Offline Inference
- The Omni class provides a Python interface for offline batched inference
- Online Inference
- Similar to vLLM, vLLM-Omni also provides a FastAPI-based server for online serving.
Vllm-Omni Endpoints
- All models expose all OpenAI-compatible endpoints such as
/v1/chat/completions. - Image :
/v1/images/generations - Video :
/v1/videos /v1/transcriptionand/v1/translation: Audio transcription/translation/v1/audio/speech: Text-to-speech (TTS) generation for supported models (e.g., Qwen3-TTS)/v1/messages: Anthropic-compatible messages (if supported_tasks include “generate”)
III. Online Inference Examples
1. Text-to-Image
# 1) Serve
vllm serve Qwen/Qwen-Image --omni --port 8091
# 2) Generate
curl -s http://localhost:8091/v1/images/generations \
-H "Content-Type: application/json" \
-d '{
"prompt": "a cup of coffee on the table",
"model": "Qwen/Qwen-Image",
"n": 1,
"size": "1024x1024"
}' | jq -r '.data[0].b64_json' | base64 -d > coffee.png2. Image-to-Image
# 1) Serve
vllm serve Qwen/Qwen-Image-Edit --omni --port 8091
# 2) Generate (edit)
curl -s http://localhost:8091/v1/images/generations \
-H "Content-Type: application/json" \
-d '{
"prompt": "turn this cat to a dog",
"model": "Qwen/Qwen-Image-Edit",
"n": 1,
"size": "1024x1024",
"image": "data:image/png;base64,..."
}' | jq -r '.data[0].b64_json' | base64 -d > edited.png3. Text-to-Video
# 1) Serve
vllm serve Wan-AI/Wan2.2-T2V-A14B-Diffusers --omni --port 8091
# Create job
curl -X POST http://localhost:8091/v1/videos \
-F "prompt=A cat runs across the street" \
-F "size=640x360" \
-F "seconds=2" \
-F "fps=12"
# Poll status (replace {video_id})
curl http://localhost:8091/v1/videos/{video_id}
# Download when ready
curl http://localhost:8091/v1/videos/{video_id}/content -o video.mp44. Image-to-Video
# 1) Serve
vllm serve Wan-AI/Wan2.2-I2V-A14B-Diffusers --omni --port 8091
# Create job with image
curl -X POST http://localhost:8091/v1/videos \
-F "prompt=A bear playing with yarn" \
-F "input_reference=@input.png"
# Poll and download same as T2V5.Text-to-Speech (TTS)
# 1) Serve
vllm serve Qwen/Qwen2.5-Omni-7B --omni --port 8091
# 2) Generate speech
curl -s http://localhost:8091/v1/audio/speech \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-Omni-7B",
"input": "Hello, this is a test.",
"voice": "Default"
}' --output speech.wav6. OmniQwen3-Omni (Multimodal: video input→ text + audio output)
# 1) Serve
vllm serve Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091
# 2) Generate (video input → text + audio output)
curl -s http://localhost:8091/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-Omni-30B-A3B-Instruct",
"messages": [
{
"role": "system",
"content": [
{
"type": "text",
"text": "You are Qwen, a virtual Cyborg developed by the Qwen Team,
capable of perceiving auditory and visual inputs, as well as generating text and speech."
}
]
},
{
"role": "user",
"content": [
{"type": "video_url", "video_url": {"url": "data:video/mp4;base64,..."}},
{"type": "text", "text": "Describe the video briefly."}
]
}
],
"extra_body": {
"sampling_params_list": [
{"temperature": 0.4, "max_tokens": 2048},
{"temperature": 0.9, "max_tokens": 4096},
{"temperature": 0.0, "max_tokens": 65536}
]
}
}' | jq -r '.choices[0].message.content' > response.jsonComing Up Next
That wraps up our Beginners vLLm-Omni intro, where we explored the key features that make vLLM-omni fast, efficient, and production-ready multi-modal serving engine. Hopefully, this little breakdown made it a little easier to grasp as the project is still growing in restless pace.
In Part 2, we’ll show you all about Diffusion models from noise to pixel, covering the research papers from 2021 to 2024!
Stay tuned for Part 2⚡

Run AI Your Way — In Your Cloud
Want full control over your AI backend? The CloudThrill VLLM Private Inference POC is still open — but not forever.
📢 Secure your spot (only a few left), 𝗔𝗽𝗽𝗹𝘆 𝗻𝗼𝘄!
Run AI assistants, RAG, or internal models on an AI backend 𝗽𝗿𝗶𝘃𝗮𝘁𝗲𝗹𝘆 𝗶𝗻 𝘆𝗼𝘂𝗿 𝗰𝗹𝗼𝘂𝗱 –
✅ No external APIs
✅ No vendor lock-in
✅ Total data control