
Intro
last year, I have dived deep into Ollama inference where I ended up building and speaking about Ollama Kubernetes deployments along with rich documentation in my ollama_lab repo and quantization article—This year’s Cloudtrhill focus is VLLM Inference which is a next level beast from a model serving standpoint. Exploring multiple inference options is time-intensive but we believe is essential for recommending the right fit to clients.
💡In this series, we aim to provide a solid foundation of vLLM core concepts to help you understand how it works and why it’s emerging as a de facto choice for LLM deployments.
While authored independently, this series benefited from the LMCache‘s supportive presence & openness to guide.
So here’s to more insights in the world of LLM inference🫶🏻
What is vLLM 🚀
vLLM (Virtual Large Language Model) is an open-source library—originally developed in the Sky Computing Lab, UC Berkeley—designed to efficiently serve LLMs. It’s built to solve one of the biggest challenges in inference: “serving massive models efficiently at scale with high throughput and low latency“. Think of vLLM as a high-performance engine that makes your favorite LLMs run faster and more efficiently when deployed in production environments. Ollama’s big brother.
Why vLLM over Ollama?
If you’re deploying LLMs in production, you should seriously consider vLLM over Ollama because:

- Higher Throughput: Serve more requests per second with the same hardware
- Lower Latency: Faster response times for users compared to other serving engines
- Scalability: Scales from a single instance to distributed deployment with 0 code change
- Resource cost Efficiency: Smarter GPU usage = lower costs
- Supports API key authentication for security purposes (ollama doesn’t)
- Production-Ready: Includes monitoring, routing, and other production grade features
- Ability to handle longer sequences
- Cloud based model serving standard: AWS, Azure, OCI, etc.
🧠What is a KV Cache?
Key-Value cache is a memory construct storing the intermediate state (Key/value store). One of the key performance optimizations in vLLM is how it handles the KV cache to speed up inference with LLMs. I wrote a whole blog about it here➡️ KV_cache explained ✍🏻
How vLLM optimize KV Cache
As sequences get longer, kv cache grows, consuming higher VRAM and creating memory fragmentation issues.
vLLM addresses this KV cache challenge with its innovative architecture.

KV_cache Optimisation examples:
- KV Cache Offloading: Moves KV caches from GPU memory to CPU when they’re not immediately needed.
- Intelligent Routing: The router can direct requests to maximize KV cache reuse.
- Paged Attention Reduces memory fragmentation, like OS memory swapping.
- Chunked prefill, Auto-Prefix caching see detail on our KV_cache explained
Core Architecture of vLLM (V0)
vLLM’s architecture consists of several key components working together:
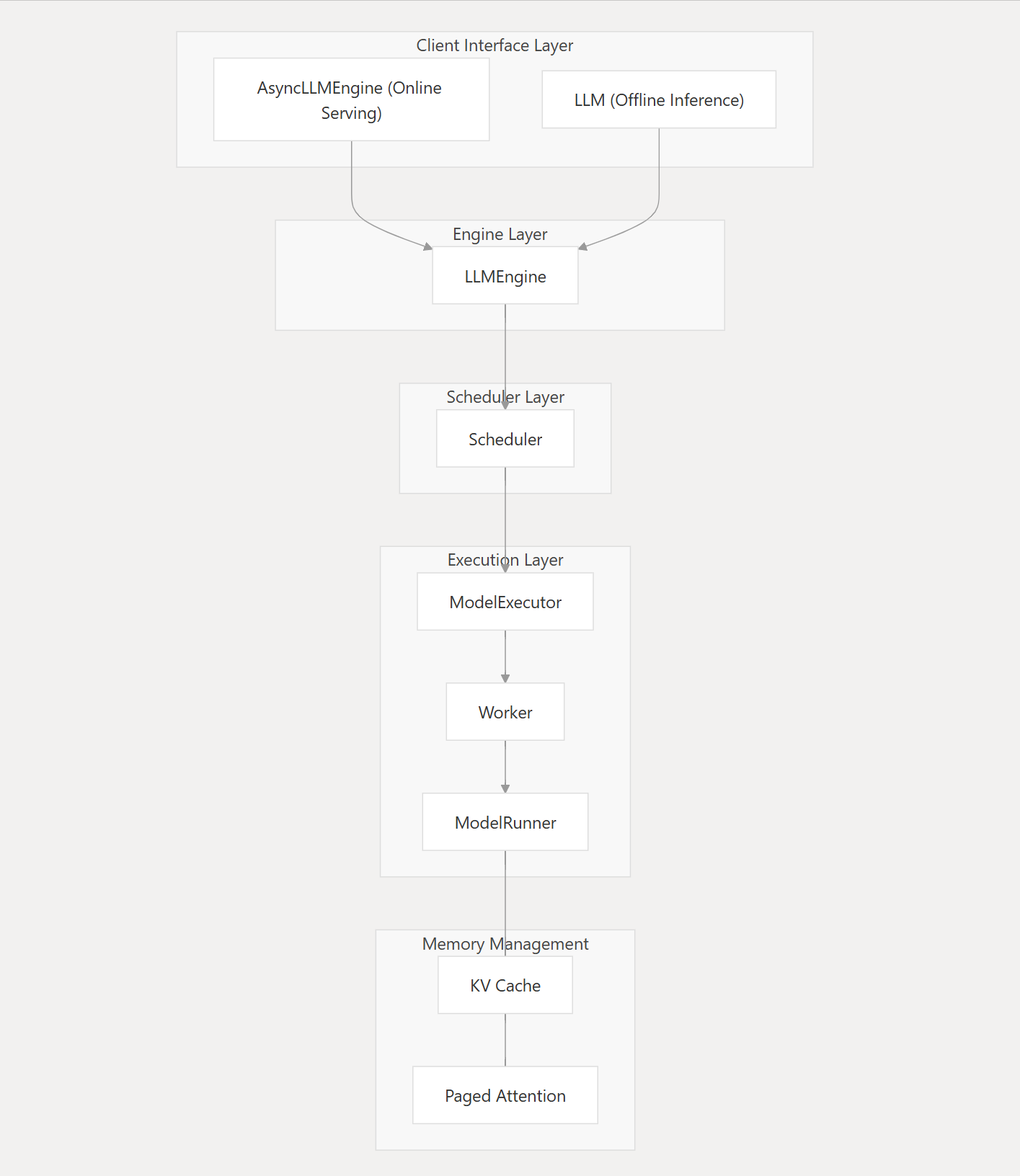
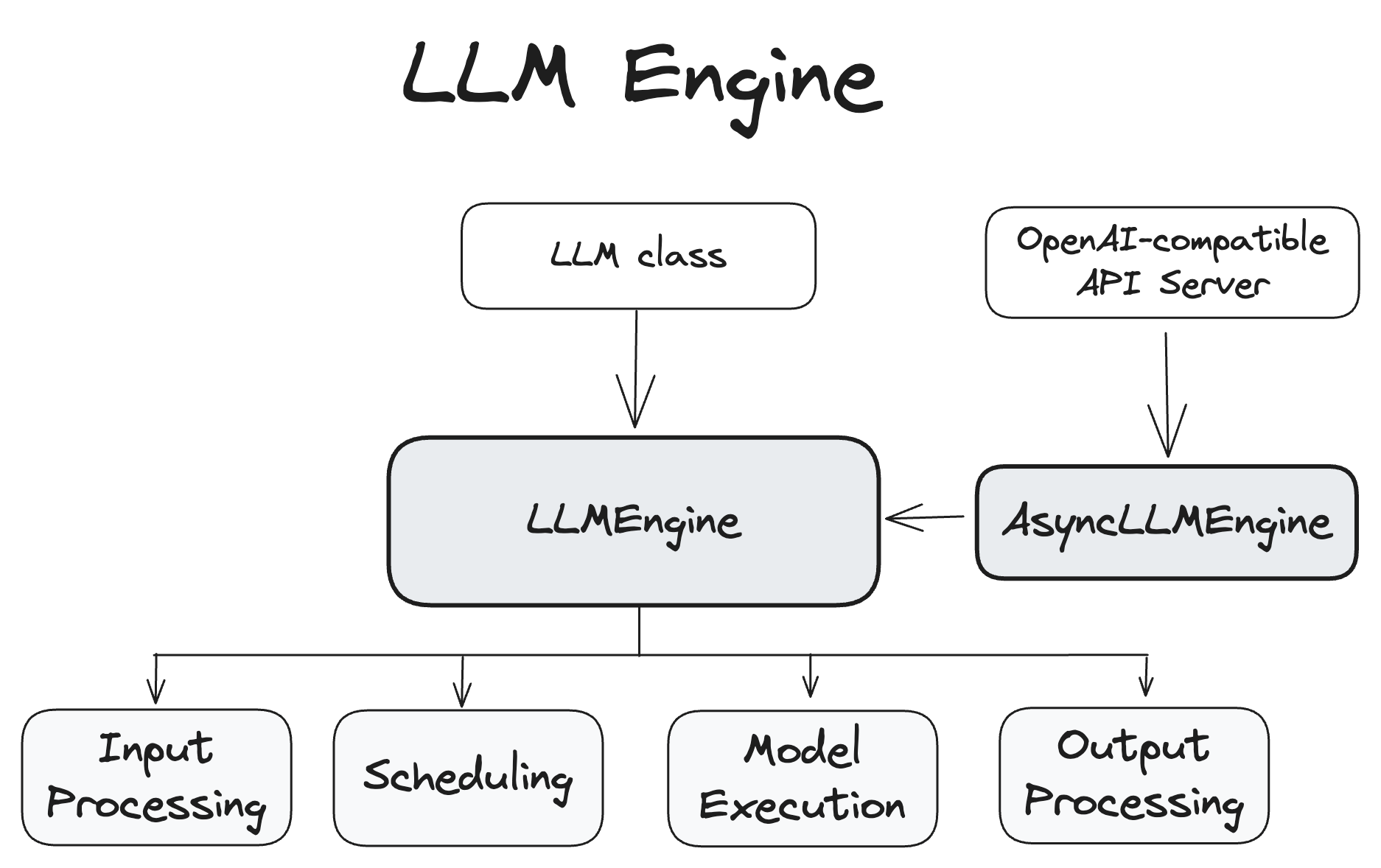
1. The Engine: Orchestrating Everything
At the heart of vLLM is the LLMEngine class, which coordinates all aspects of the inference process:
- Processes input requests (prefill).
- Manages the scheduling of these requests.
- Coordinates model execution.
- Handles output processing .
⚖️Offline and Online inference
There are two ways to interact with LLMs in vLLM

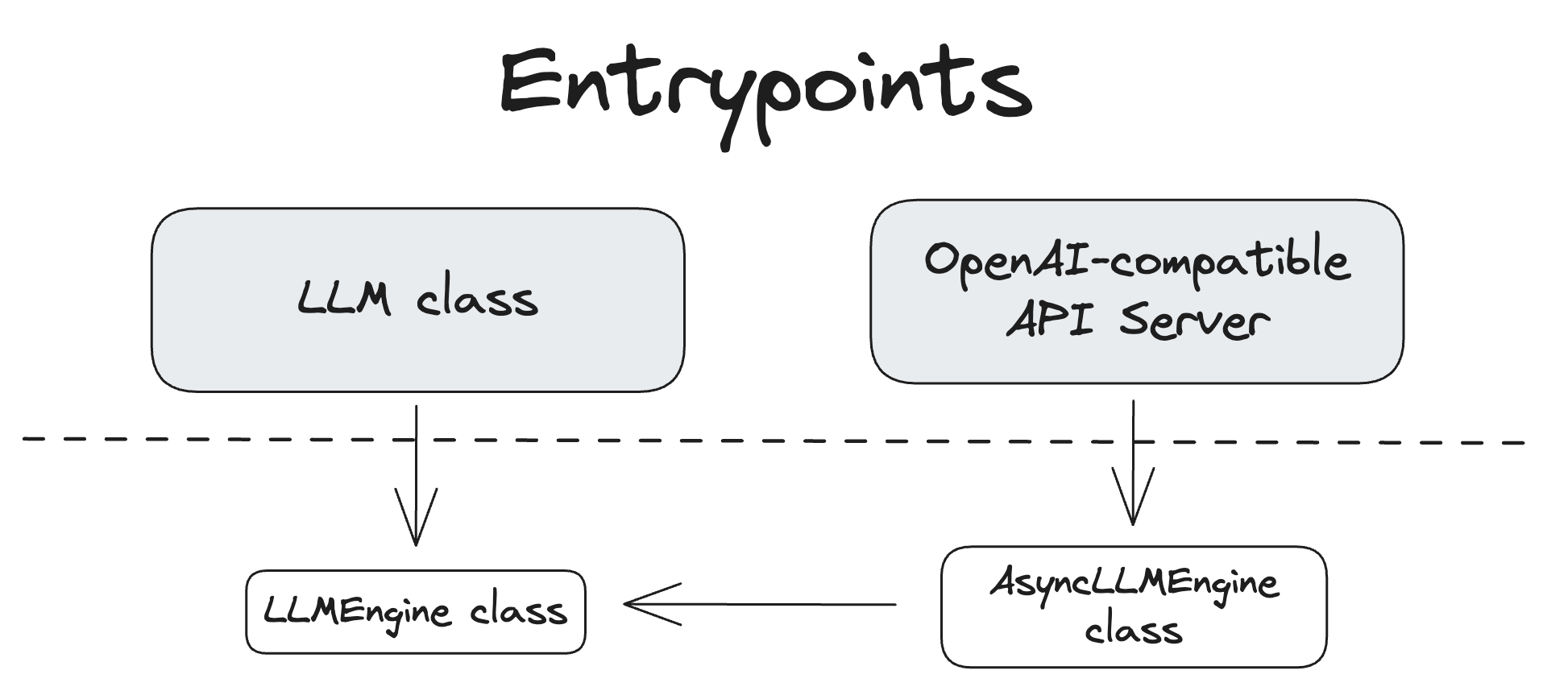
A. Offline inference (LLMClass)
This is the client interface used for synchronous batch processing of prompts in offline scenarios
- For cases where you want to process a batch of prompts at once.
- It’s a Native inference (LLM Class) with no separate inference server.
- Without real-time requirements (multi-turn conversation).
B. Online inference (AsyncLLMEngine)
This is the client interface that provides asynchronous API for online serving
- For real-time, interactive use cases like chatbots.
- Handles multiple concurrent requests and stream outputs to clients.
- Integration with APIs: OpenAI-compatible API server along with lmserve cli command.
Examples
vllm serve NousResearch/Meta-Llama-3-8B-Instruct --dtype auto --api-key token-abc123Using Python module-based API server launch
$ python -m vllm.entrypoints.openai.api_server --model meta-llama/Meta-Llama-3-8BClient (REST)
$ curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "meta-llama/Meta-Llama-3-8B",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="token-abc123",
)
completion = client.chat.completions.create(
model="NousResearch/Meta-Llama-3-8B-Instruct",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
2. Scheduling layer
The scheduler determines which requests to process in each iteration, managing resources and request priorities.
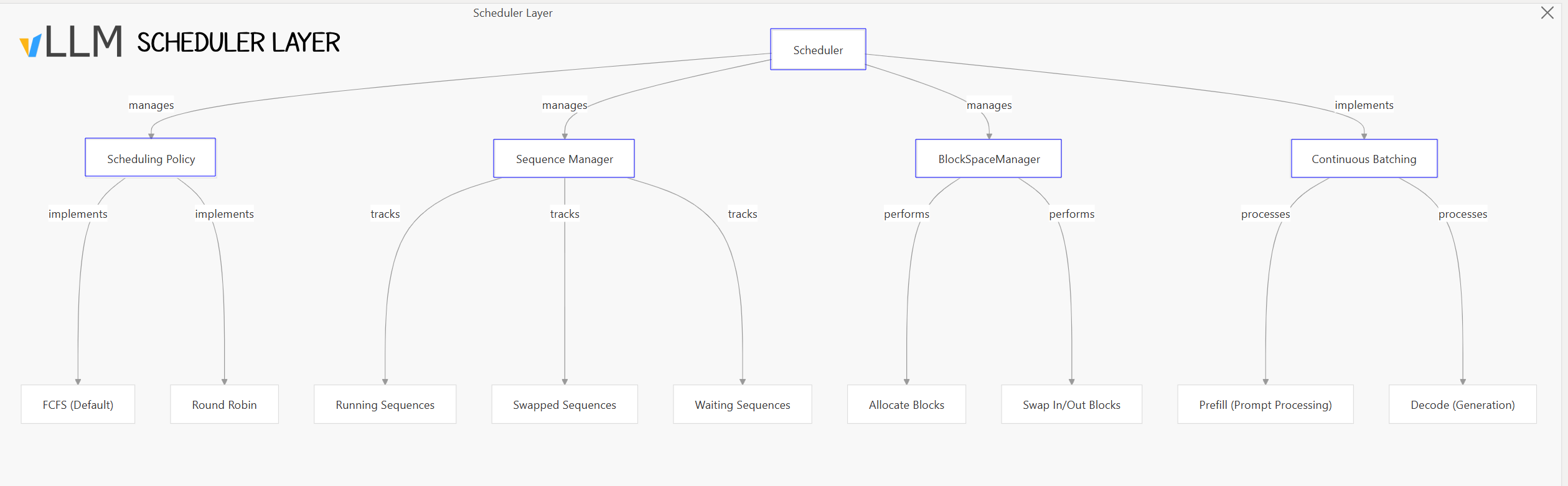
It makes decisions about:
- Which sequences to run (prefill vs. decode)
- Block allocation and swapping
- Batching and prioritization
Components
- Sequence Manager: Tracks, prioritize sequences & manages sequence groups for batched processing
- ➡️state: running, waiting, swapped
- Block Space Manager: Allocates KV cache blocks to sequences, Handles GPU/CPU blocks swapping
- Continuous Batching: Interleaves prefill (prompt processing) and decode (generation) operations
- Scheduler Outputs: Contains metadata about sequence groups to process
- Specifies memory operations (blocks to swap in/out/copy)

3. Execution layer
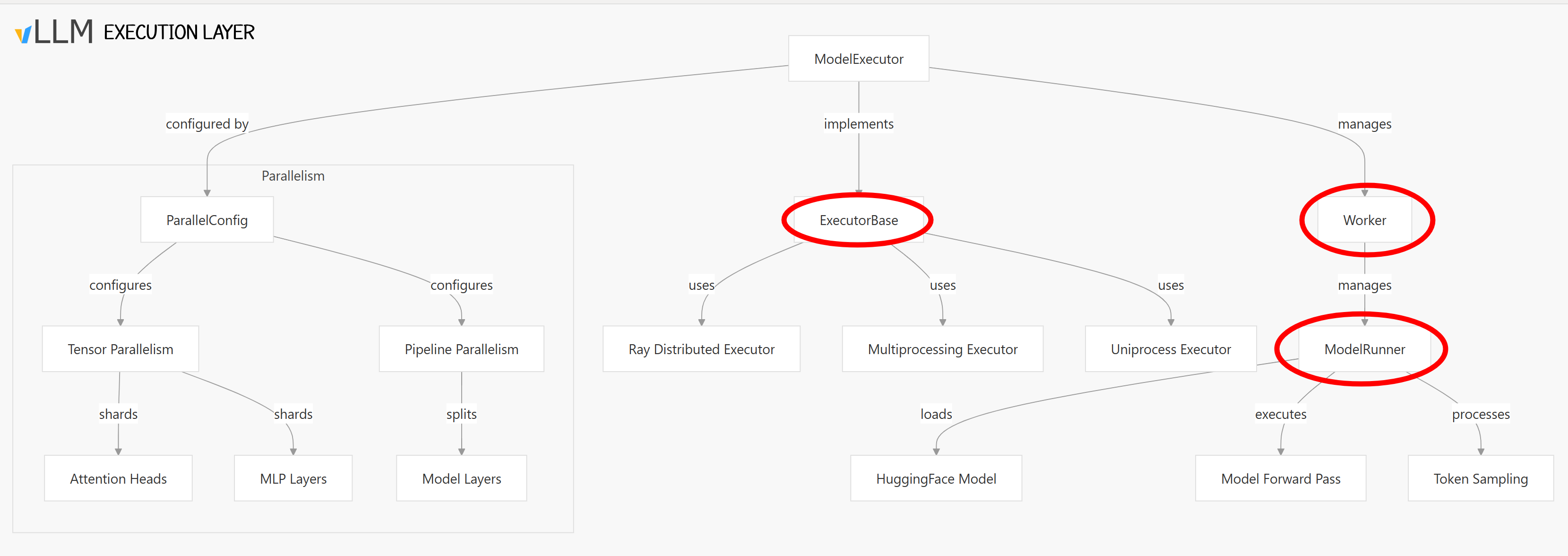
The execution layer handles model inference, sitting between the scheduler (which chooses tasks) and memory management (which manages KV cache), ensuring efficient LLM execution. It consists of several key components
3.1. Model Executor
Is the central component that manages model execution locally or across distributed GPUs. It is responsible for:
- Initializing the model weights.
- Executing forward passes through the model.
- Managing distributed execution across multiple GPUs/TPUs.
- Handling KV cache initialization.
- Supports multiple backends (Ray, Multiprocessing, Uniprocess).
- Coordinates workers for model execution across devices.
3.2. Workers
The Worker executes a partition of the model on a single GPU (or part of a GPU) and is responsible for:
- Initializing the model and GPU resources.
- Managing the KV cache through the
CacheEngine. - Executing model forward passes via the
ModelRunner. - Processing sampling operations.
3.3. Model Runner
Every model runner extends a worker, it handles the execution of LLMs on GPU/TPU hardware. It’s responsible for:
- Model Execution: takes model inputs and produces outputs.
- Input Preparation: Tokenizing and metadata.
- Managing hardware resources like KV cache.
- Handling optimizations: Capturing CUDA graphs, mixed precision, kernel fusion.
4. Memory management layer
This layer optimizes the usage of limited GPU memory to support efficient & concurrent inference. It’s responsible for:

KV Cache Management: Manages key-value cache blocks for transformer attention.
Block Management: Allocates, deallocates, and swaps memory blocks.
Memory Profiling: Analyzes memory usage to determine optimal allocation.
Memory Optimization: Implements techniques like FP8 KV cache to reduce memory footprint.
LMCache Integration: Provides KV cache offloading capabilities.
Paged Attention: The Secret Sauce
PagedAttention is the core innovation that efficiently manages the attention key-value memory.
- Treats KV cache as non-contiguous memory blocks.
- Maps logical sequence positions to physical memory locations.
- Enables more efficient memory utilization.
- Reduces memory fragmentation.
- Supports dynamic sequence lengths.
vLLM key Components Summary v0
| Component | Purpose | Key Classes |
|---|---|---|
| Engine | Core orchestration | LLMEngine, AsyncLLMEngine, LLM |
| Worker | Model execution | Worker, ModelRunner, GPUModelRunner |
| Scheduler | Request scheduling | Scheduler |
| Memory Management | KV cache optimization | CacheEngine, BlockSpaceManager |
| Configuration | System settings | VllmConfig, ModelConfig, CacheConfig |
| Input Processing | Request handling | InputProcessor, Processor |
| Output Processing | Response generation | OutputProcessor |
| Distributed | Multi-GPU/node execution | ExecutorBase, RayDistributedExecutor |
vLLM Configuration Basics
vLLM uses the VllmConfig class as its main config hub, letting users control:
- Model Specification: Which model to serve and from where to load it.
- Resource Allocation: How many GPUs, CPU cores, and memory to allocate.
- Inference Parameters: Settings like chunk size, data type, and maximum sequence length.
- CacheConfig: Manages KV cache memory settings.
- ParallelConfig: Handles distributed execution settings .
- SchedulerConfig: Controls request scheduling behavior.
- SpeculativeConfig: Controls speculative decoding features .
A basic configuration typically includes:
modelSpec:
- name: "llama3"
modelURL: "meta-llama/Llama-3.1-8B-Instruct"
requestGPU: 1
vllmConfig:
maxModelLen: 16384
dtype: "bfloat16"These are defined in vllm/envs.py and include:
VLLM_USE_V1: Controls whether to use V1 architecture (default is True)VLLM_TARGET_DEVICE: Specifies the target device (cuda, rocm, neuron, cpu)VLLM_CACHE_ROOT: Sets the root directory for vLLM cache files
🚀Coming Up Next (Pt 2)
In the next post of our series, we’ll dive deeper into vLLM performance optimization techniques and features such as PagedAttention, attention backends(Flash Attention/FlashInfer), Speculative decoding , Chunked prefill, Speculative decoding, Disaggregated Prefill and more
Stay tuned for Part 2: “VLLM Performance Optimization features”!
Reference

Run AI Your Way — In Your Cloud
Want full control over your AI backend? The CloudThrill VLLM Private Inference POC is still open — but not forever.
📢 Secure your spot (only a few left), 𝗔𝗽𝗽𝗹𝘆 𝗻𝗼𝘄!
Run AI assistants, RAG, or internal models on an AI backend 𝗽𝗿𝗶𝘃𝗮𝘁𝗲𝗹𝘆 𝗶𝗻 𝘆𝗼𝘂𝗿 𝗰𝗹𝗼𝘂𝗱 –
✅ No external APIs
✅ No vendor lock-in
✅ Total data control
𝗬𝗼𝘂𝗿 𝗶𝗻𝗳𝗿𝗮. 𝗬𝗼𝘂𝗿 𝗺𝗼𝗱𝗲𝗹𝘀. 𝗬𝗼𝘂𝗿 𝗿𝘂𝗹𝗲𝘀…
🙋🏻♀️If you like this content please subscribe to our blog newsletter ❤️.