
Intro
Too often, machine learning concepts are explained like a mathematician talking to other mathematicians—leaving the rest of us scratching our heads. One of those is kv_cache, a key technique that makes large language models run faster and more efficient.
This blog is my attempt to break it down simply, without drowning in dark math :). If you’ve ever wondered what kv_cache actually does, you’re in the right place. Let’s make it click.
I. What is a KV Cache?
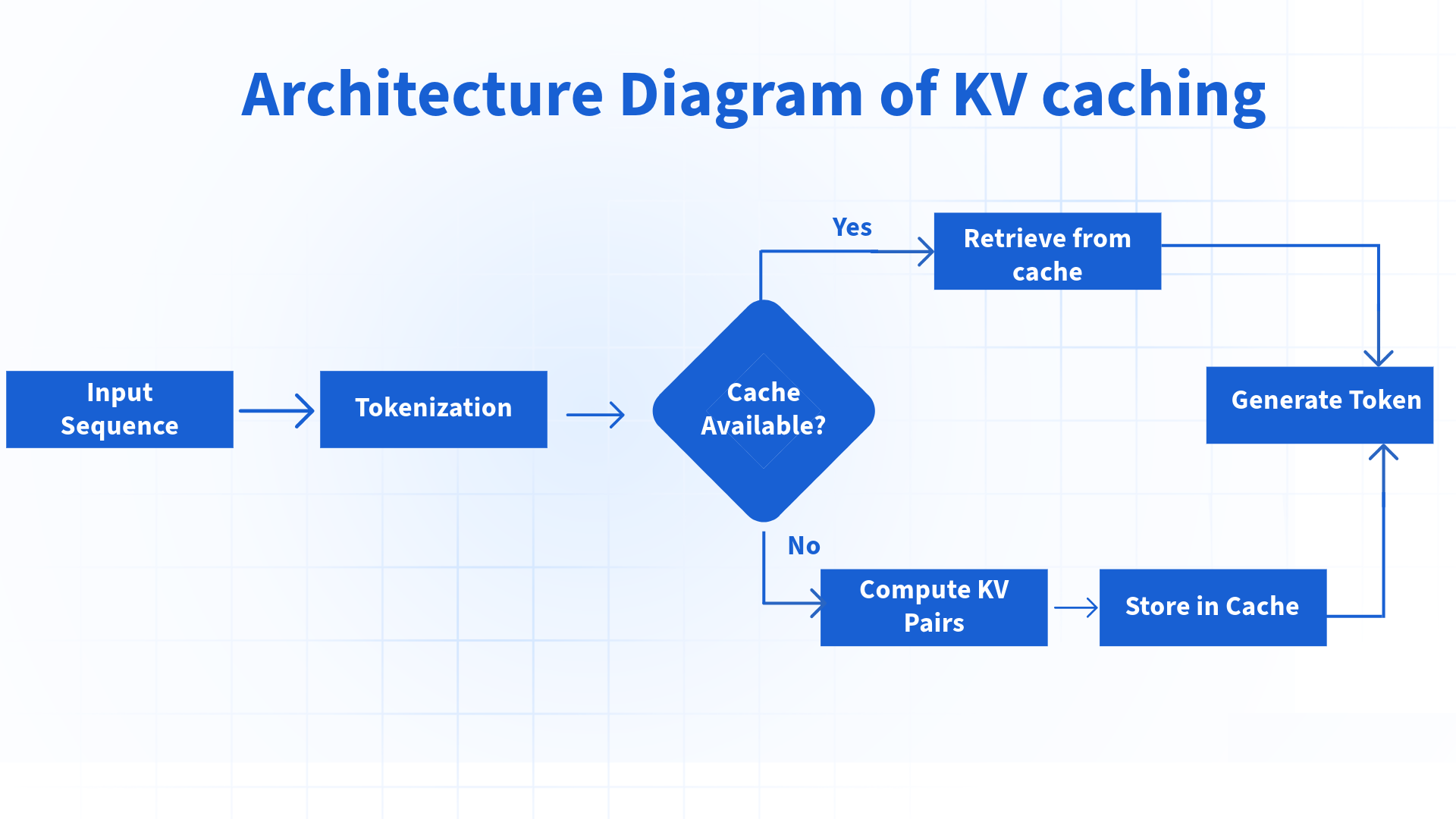
One of the key performance optimizations in vLLM is how it handles the KV (Key-Value) cache as it’s one of the most commonly-used tricks for speeding up inference with decoder based LLMs (i.e GPT).
In old autoregressive language models, when generating text token by token, the model needs to compute attention over all previous tokens. The KV cache stores these intermediate computations so they don’t need to be recalculated for each new token, dramatically speeding up inference.
Benefits:
- More efficient use of GPU memory
- Higher throughput for text generation
- Ability to handle longer sequences
Word Chain Game Analogy 🎲
Imagine a game where you have to recite other players words and add a new one that starts with the last word’s letter.

KV Cache is like having a notepad to write all words that have been said and their context instead of memorizing them.
Now, let’s relate this to the attention mechanism in AI:
🧠Attention in transformers
A word has its own embedding (vector), but each time it’s associated to another token its embedding gets enriched.
Example: the word “Tower” preceded by “Eifel” means a whole different context or what we call embedding direction.
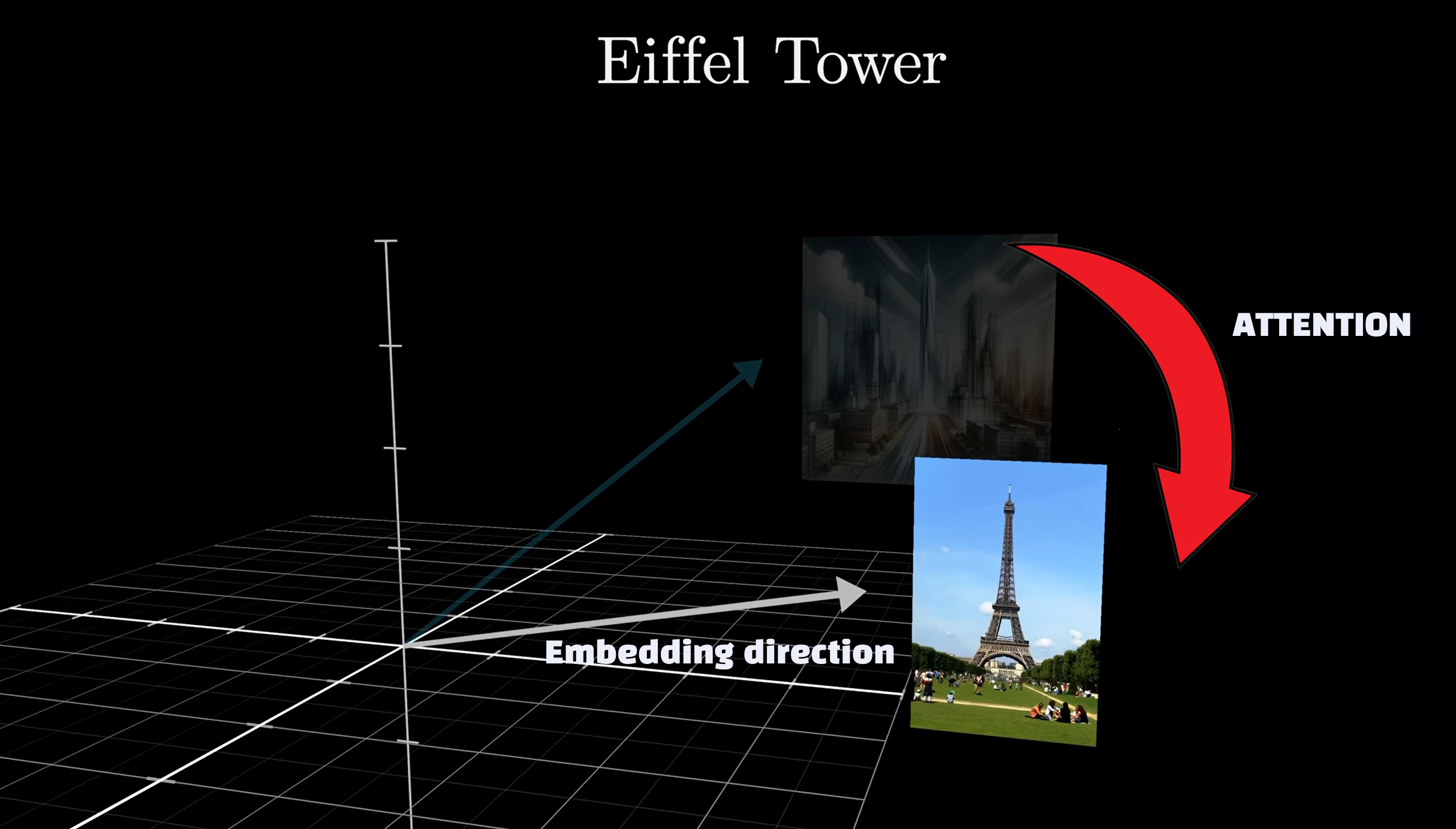
A later word will never influence a previous one. You can learn more about attention mechanism in this pure gold video
Now back to Our Attention formula and how it’s linkedn to KV Cache :
- Queries (Q): Are like the current word (input token) you’re focusing on in the chain. [asks question]
- Keys (K): These represent all possible previous words you could connect to. [answers to questions]
- Values (V): Are the actual words or information associated with each key. [relevance of answers vs question]
- Formula
- QKᵀ: Measures the similarity/alignment between the current word and all previous words (dot product).
- √dₖ: A scaling factor to ensure the values don’t become too large.
- Softmax: Converts most relevant connections into probabilities(values between [0,1]).
- V: The actual information or words that are combined based on these probabilitie.
Below animation shows the difference in scenario between utilizing a KV cache and not

TL;DR
- KV cache: LLM’s short-term memory for conversation details.
- KV cache stores the key embeddings (words and their context) of everything you’ve already told it (tokens).
- Your prompt(prefile) is the step that takes most of the time storing KV pairs.
- Each new generated token will reuse previously cached context from earlier tokens.
The below video shows a simple example around the Attention formula and how the kv cache improves memory usage:
II. How vLLM Optimizes KV Cache 🚀
- KV Cache Offloading: Moves KV caches from GPU memory to CPU when they’re not immediately needed.
- Intelligent Routing: The router can direct requests to maximize KV cache reuse.

LMCache team from UChicago is a key open-source contributor, focused on KV cache optimization within the vLLM ecosystem. They’re also behind Kubernetes native production-stack implementation of vLLM which will cover soon.
Other KV Cache Optimization Techniques
🤚🏼At this point we passed the foundation part and venture into advanced section. You don’t need to understand these concepts but its a good reference.
Why does LLM serving face a “combinatorial explosion” of attention kernels?
Every unique permutation of the serving stack requires a dedicated, manually optimized CUDA/Triton kernel:
1. Cache Compression (Quantization & Pruning)
- Use int4/int8 precision for keys/values to reduce memory (e.g.,
QuantizedCachefrom Hugging Face). - Prune less important KV entries dynamically at generation time(e.g., Scissorhands, H2O).
- Cuts memory usage with minimal accuracy loss.
2. Paged Attention / KV Partitioning

- Split KV cache into fixed-size blocks instead of one large tensor.
- Paged attention use a lookup table to fetch only needed blocks per attention step.
- Reduces memory fragmentation, imitating OS memory swapping, supports larger batches.
- Enables KV sharing between parallel similar prompts (many logical kv blocks to 1 physical kv block) .
3. Prefix Caching (KV Cache Reuse)
- Caches KV outputs from the initial prompt (prefill phase) for reuse.
- Speeds up decoding by avoiding re-computation of prompt tokens.
- Especially helpful in serving repeated or similar prompts (e.g., RAG systems).
- Works for batch requests and few-shot examples.
- technics: Automatic Prefix Caching , RadixAttention (organize past KV caches in a prefix-tree)
4. Memory Tuning & Parallelism
- Adjust
gpu_memory_utilizationto reserve more space for KV cache. - Increase tensor or pipeline parallelism to reduce per-GPU weight shards & increase KV load.
- Lower concurrent batch size to fit within memory limits.
- Monitor for cache evictions or preemptions to fine-tune further.
5. Static / Pre-allocated Cache (JIT friendly)
- Pre-allocate a fixed-size KV cache buffer up to max context length.
- A StaticCache Improves Just-In-Time compilation compatibility (e.g.,
torch.compile). - Prevents out-of-memory errors from dynamic growth.
- Optimizes memory layout and latency.
6. Sliding Window & “Sink” Caches
- Drop old tokens that have little influence.
- Only keep recent N tokens’ KV entries (sliding window, i.e mistral).
- Retains only a few “sink” tokens (those with high attention weight) from old cache.
- Keeps memory usage bounded even for very long inputs.
- Eviction-based strategies that cap KV growth, useful for streaming.
7. Offloading to CPU
- Move most of the KV cache to CPU RAM, keeping only the current layer on GPU.
- Example: Hugging Face’s
OffloadedCacheandOffloadedStaticCache. - Useful for long contexts without running out of GPU memory.
- Trades off some speed for memory savings.
Conclusion
kv_cache isn’t just a technical detail—it’s one of the key reasons modern LLMs can respond quickly and take more context. By reusing past work instead of recalculating everything from scratch, it turns inference into a much faster and smarter process. Hopefully, this breakdown made it a little easier to grasp.

Run AI Your Way — In Your Cloud
Want full control over your AI backend? The CloudThrill VLLM Private Inference POC is still open — but not forever.
📢 Secure your spot (only a few left), 𝗔𝗽𝗽𝗹𝘆 𝗻𝗼𝘄!
Run AI assistants, RAG, or internal models on an AI backend 𝗽𝗿𝗶𝘃𝗮𝘁𝗲𝗹𝘆 𝗶𝗻 𝘆𝗼𝘂𝗿 𝗰𝗹𝗼𝘂𝗱 –
✅ No external APIs
✅ No vendor lock-in
✅ Total data control
𝗬𝗼𝘂𝗿 𝗶𝗻𝗳𝗿𝗮. 𝗬𝗼𝘂𝗿 𝗺𝗼𝗱𝗲𝗹𝘀. 𝗬𝗼𝘂𝗿 𝗿𝘂𝗹𝗲𝘀…
🙋🏻♀️If you like this content please subscribe to our blog newsletter ❤️.