
Intro
We often hear about RAG (Retrieval-Augmented Generation) and vector databases that store embeddings, but we fail to remember what exactly are embeddings used for and how they work. In this post, we’ll break down how embeddings work – in the simplest way possible (yes, like you’re 5 🧠📎).
I. What is an Embedding?
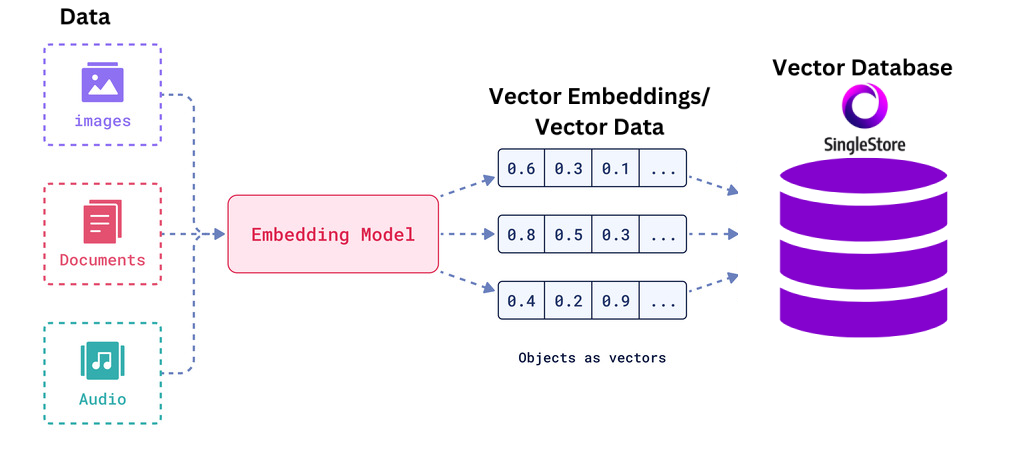
Basically, it is the process of converting data (like text, media) into numerical vectors (a list of numbers).
Purpose
This numerical representation makes it easier for AI models to understand the semantic relationships between different pieces of data and process them. As similar concepts, or words have similar vectors and placed closer together.
Example:
- The word “dog” might be converted into a vector like
[0.1, 0.3, 0.5] - The word “cat” might be
[0.2, 0.3, 0.4]showing they are related but not identical. - Same with “Hot dog” 🌭 and “Shawarma” 🥙
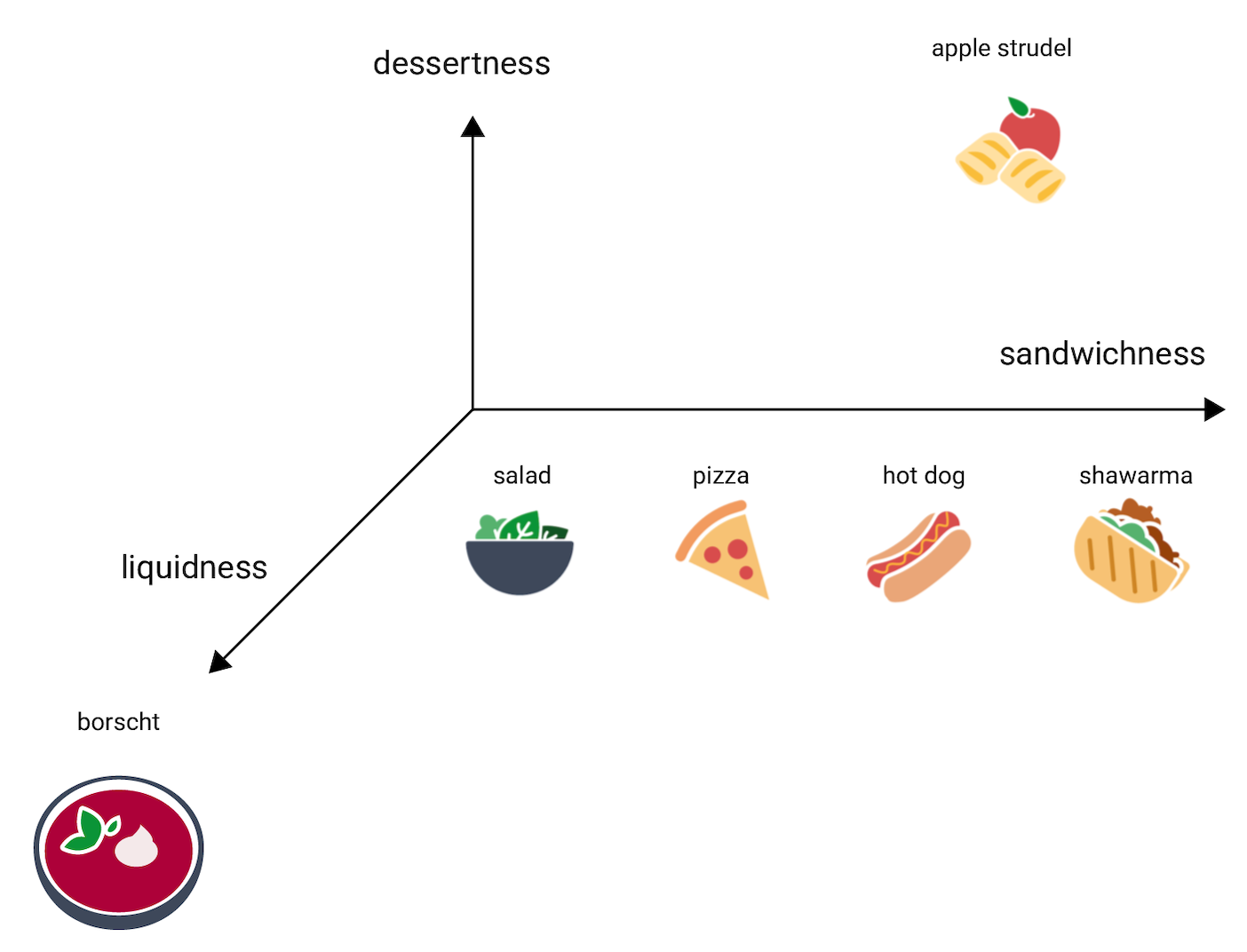
For instance, in text processing, word embeddings map words with similar meanings to similar vector representations. This makes it easier for machine learning models to analyze and understand text.
Simple Command example
Let’s take a popular developer command like a git commit for example and break it down the same way.
Input
git commit -m "Initial commit"Now imagine we pass this through an embedding model. It turns each token (word/command) into a vector, a list of numbers that represent meaning.
Embedding
"git"→[0.24, 0.63, 0.71, ...]"commit"→[0.41, 0.88, 0.55, ...]"-m"→[0.09, 0.47, 0.60, ...]"Initial commit"→[0.35, 0.92, 0.48, ...]
🧠Embeddings in LLM transformers Attention
A word has its own embedding (vector), but each time it’s associated to another token its embedding gets enriched.
Example: the word “Tower” preceded by “Eifel” means a whole different context or what we call embedding direction which means a different vector value.
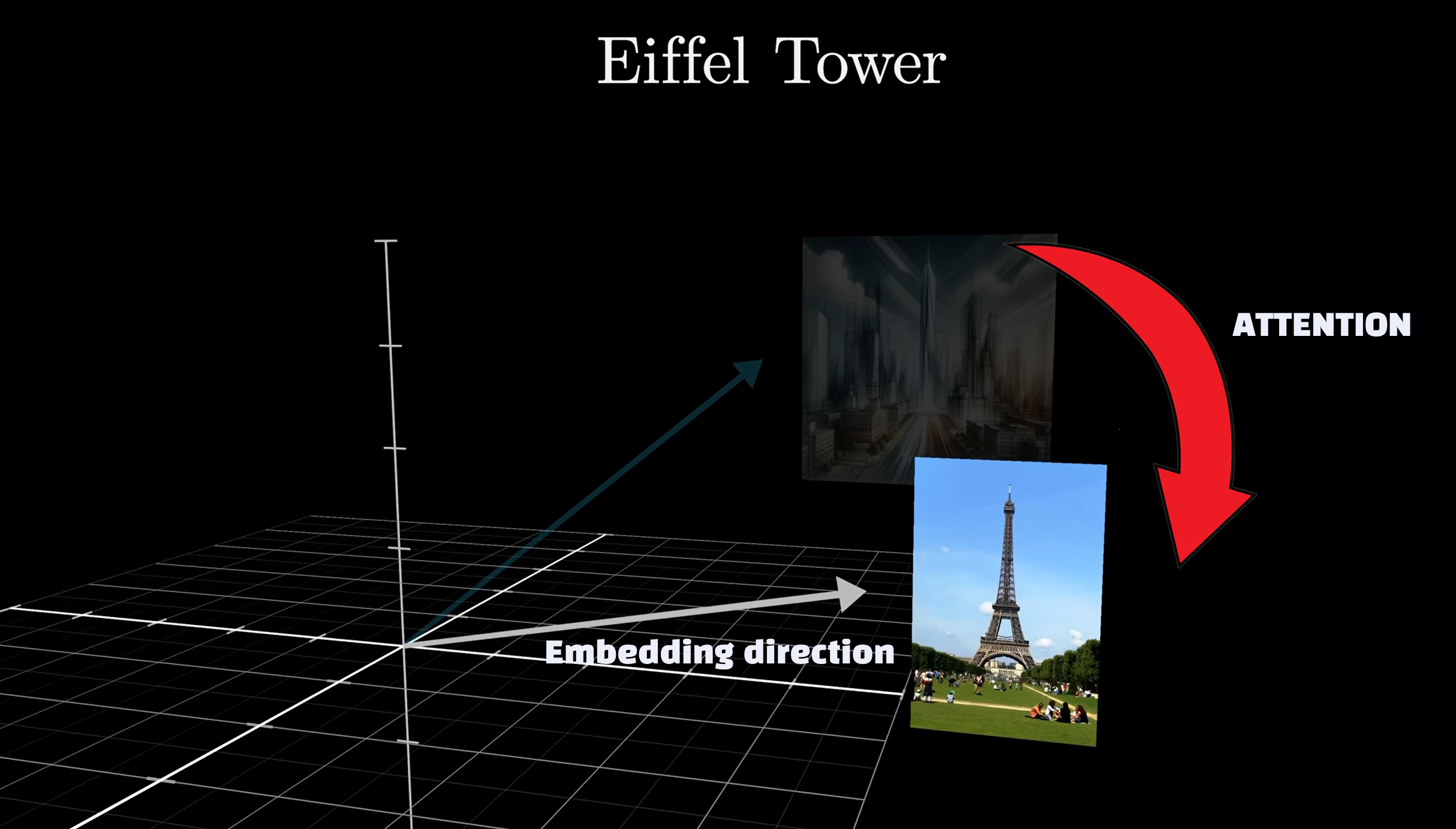
A later word will never influence a previous one. You can learn more about attention mechanism in this video
🧀Right Chunk Size for Context
When dealing with embeddings, particularly in the context of large documents or scripts, it’s crucial to break down the text into chunks before generating embeddings. The right chunk size depends on several factors:

1. Model Type (Context):
Different models have different context windows (i.e Llama-3 have a token limit of 8k tokens). You need to ensure that the chunk size fits within the model’s context window.
2. Text Structure:
It’s often best to chunk the text logically, such as by sentences, paragraphs, or sections, to preserve the context.
3. Use Case:
If you need to preserve semantic meaning over longer text, smaller chunks may help maintain coherence. However, if you want to capture larger context, larger chunks may be appropriate.
Example of Chunk Size
For a model with a context window of 2048 tokens:

- Small Chunk:
200-300 tokens(a few sentences or a paragraph). This is useful if you want precise control over each part of the text. - Medium Chunk:
500-700 tokens(a longer paragraph or several short paragraphs). This balances detail and context. - Large Chunk:
1000-1500 tokens(a full section or multiple paragraphs). Use this if you need to retain broader context at the cost of some granularity.
🫗Chunk overlaps

Overlapping improves retrieval rate. Say you’re trying to get an answer for a query using a specific line of text and have minimal/no overlap, the answer could be split between 2 chunks and not be retrievable.
This can lead to retrieve literally the opposite meaning from the source.
Example:
Chunk2 “.. I love cats..blahblah.”
🤔 Question: Does Mariah love cats ?
YES (Wrong)
Reason: 0 overlap.
💡However if you chunk with significant overlap you won’t “lose” information due to splitting.
✂️ Text Splitters
Text Splitters like nlp-sentencize are lightweight tools that break long paragraphs into individual sentences, making it easier to split text in NLP workflows. Perfect for chunking, embedding, or just making your text processing smarter. 📄
Example on a Web UI (Page-Asist)

TL;DR
Embedding is a way to represent data (like text) as numerical vectors in a continuous space.
Chunk Size depends on the model’s token limit, the text structure, and the specific use case.
II. Vector Databases (Vector DBs)

Definition
A vector database is a specialized database that stores and retrieves these embeddings (vectors). It allows for efficient searching and matching of data based on their vector similarities. This is useful for finding related context quickly.
Example:
If you search for "pet" in a vector database, it might find vectors close to "dog" and "cat" because they are semantically related.
III. Embedding models
Embedding models transform text into dense vectors that capture meaning, context, and relationships.
These vectors power tasks like:
- Semantic Understanding: Similar meanings yield similar vector positions.
- Efficient Search: Enables fast, relevant retrieval using vector similarity.
- Model Enhancement: Helps larger systems like RAG better understand and respond to user inputs.
🔎 Common & Popular Embedding Models
| Model | Detail |
|---|---|
| nomic-ai/nomic-embed-text | Extremely fast embedding model for large-scale text-to-vector transformation. |
| MXBAI/mxbai-embed-large | Large, high-capacity model designed for nuanced and detailed text embeddings. |
| all-MiniLM-L6-v2 | Lightweight and efficient — widely used for semantic search and sentence similarity. |
| Qwen3-Embedding-8B | Multilingual LLM that supports embeddings with high contextual depth. No.1 in the MTEB multilingual leaderboard |
| EmbeddingGemma | A state-of-the-art model for multilingual tasks, with excellent performance. Designed specifically for on-device AI |
| BAAI/BGE-M3 (GEMME) | State-of-the-art multilingual embedder; ranked highly on BEIR and MTEB benchmarks. |
Conclusion
Embeddings aren’t just a buzzword, they’re how LLMs “remember” things beyond their training. By turning text into numbers and using vector databases to find what’s related, embeddings power smarter, context-aware responses in systems like RAG. Hopefully, this gave you a clearer picture.
TL;DR
Embedding: Turns text into numbers (vectors) so machines can understand it.
Embedding Models: Tools like nomic-embed-text or BGE-M3 generate those vectors.
Vector DBs: Store & search these vectors to retrieve related info fast.

Run AI Your Way — In Your Cloud
Want full control over your AI backend? The CloudThrill VLLM Private Inference POC is still open — but not forever.
📢 Secure your spot (only a few left), 𝗔𝗽𝗽𝗹𝘆 𝗻𝗼𝘄!
Run AI assistants, RAG, or internal models on an AI backend 𝗽𝗿𝗶𝘃𝗮𝘁𝗲𝗹𝘆 𝗶𝗻 𝘆𝗼𝘂𝗿 𝗰𝗹𝗼𝘂𝗱 –
✅ No external APIs
✅ No vendor lock-in
✅ Total data control
𝗬𝗼𝘂𝗿 𝗶𝗻𝗳𝗿𝗮. 𝗬𝗼𝘂𝗿 𝗺𝗼𝗱𝗲𝗹𝘀. 𝗬𝗼𝘂𝗿 𝗿𝘂𝗹𝗲𝘀…
🙋🏻♀️If you like this content please subscribe to our blog newsletter ❤️.