

Intro
Over the past year, I was drowning into GitHub PRs, half-baked redit discussions, videos, and scattered docs trying to decode the chaos of quantization for Large Language Models (LLMs). Everyone was talking about running Llama models on a laptop, but no one was explaining how it actually worked — and forget about finding proper research papers from the minds around tools like llama.cpp (i.e Iwan Kawrakow).
At the end I curated enough data to provide a foundational understanding of quantization principles, addressing common confusions and answering questions you might have hesitated to ask.
So here’s everything I wish someone had told me a year ago.
Quantization World
💡LLaMA is “open-weight” not open-source
You might think LLaMA is open-source, but it’s not. While the model weights are free, Meta never shared the training dataset, making it open-weight, not really open-source. Mixtral models on the other hand are 100% open source.
The probable reason they didn’t share the training data(15 trillion tokens) is to protect against copyright law suits.
But thanks to Knowledge Fusion by Merging Weights of Language Models, it’s now possible to combine weights from different models without needing the original training dataset.
Quantization
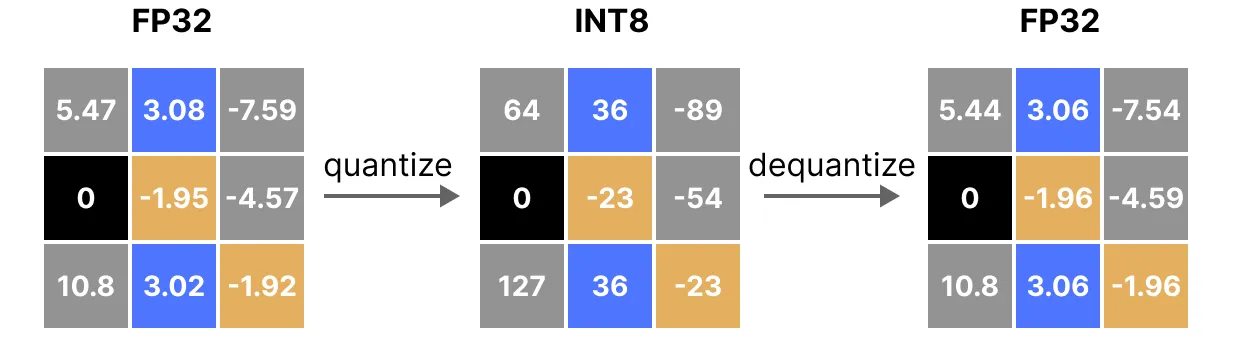
Quantization is like shrinking really big numbers (used in AI models) into smaller ones to save space and make things faster. Instead of using super-precise numbers (floating points), we use simpler numbers (whole numbers or integers). This helps the AI work better on devices with less memory, power and compute, like your phone or laptop, and other edge devices.
- Below is a representation of accuracy loss from 32bit to 16bits/Bfloat16 (lower the bit => less weight precision)
Categories of LLM Quantization:
- Post-Training Quantization: Fast, needs little training data, but loses some precision.
- Quantization-Aware Training: Fine-tunes with quantization in mind, converting weights during training.
Weight Quantization: Model weights, are quantized to lower precision.
Activation Quantization: targets Intermediate activation values, which are the outputs of each layer during inference.
✨ What are Scaling Factors?
Think of scaling factors like a zoom function for numbers. When we shrink big numbers into tiny ones (32bit to 4-bit values) to save space, we need a way to stretch them back to something useful. Scaling factors help do that, making sure the small numbers still approximate the original floating-point weights, so the model doesn’t lose too much accuracy during quantization.
Scaling factor determines how floating-point values map to low bit numbers ( i.e INT8 range {-127 to 127}).
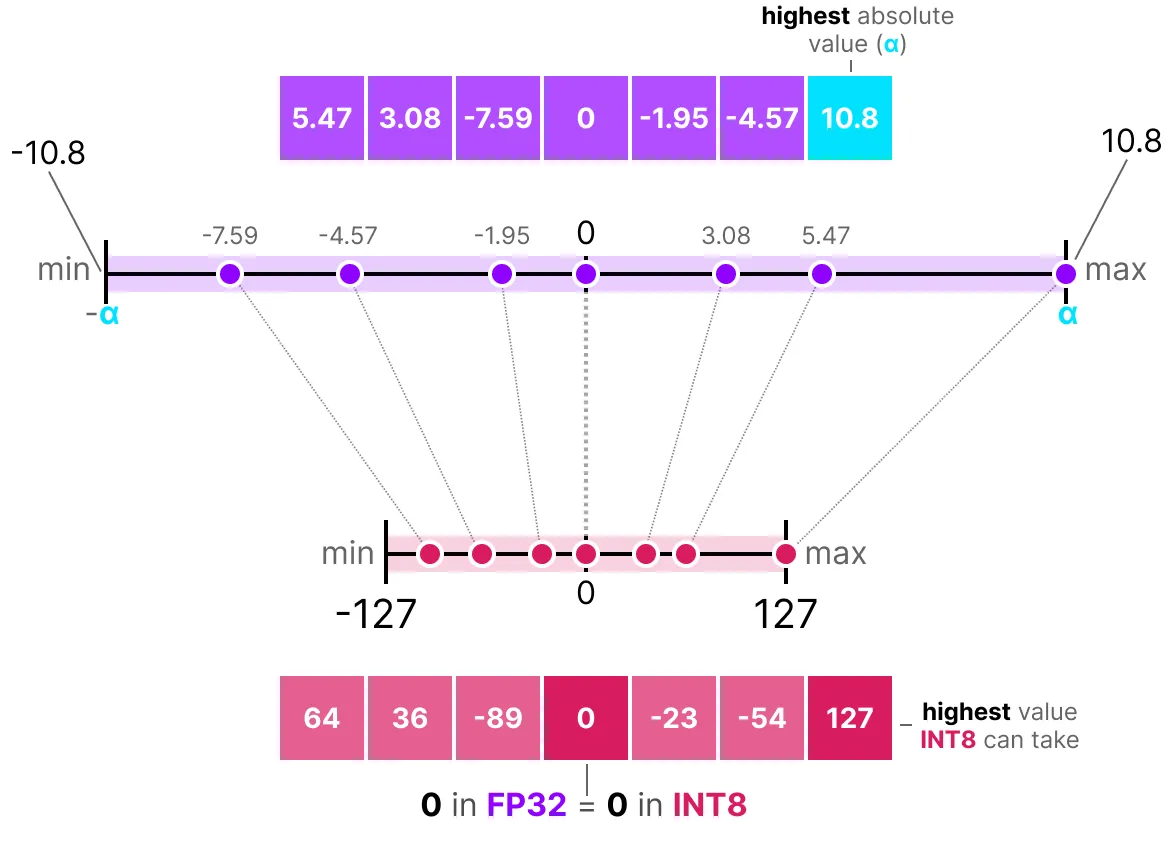
How to find a scaling factor : In symmetric Quantization for instance, zero in the full precision(32) is exactly zero in the quantized equivalent.
For INT8, the S formula is : 127(max absolute value) divided by the highest weight number (10.8) the weights matrix .
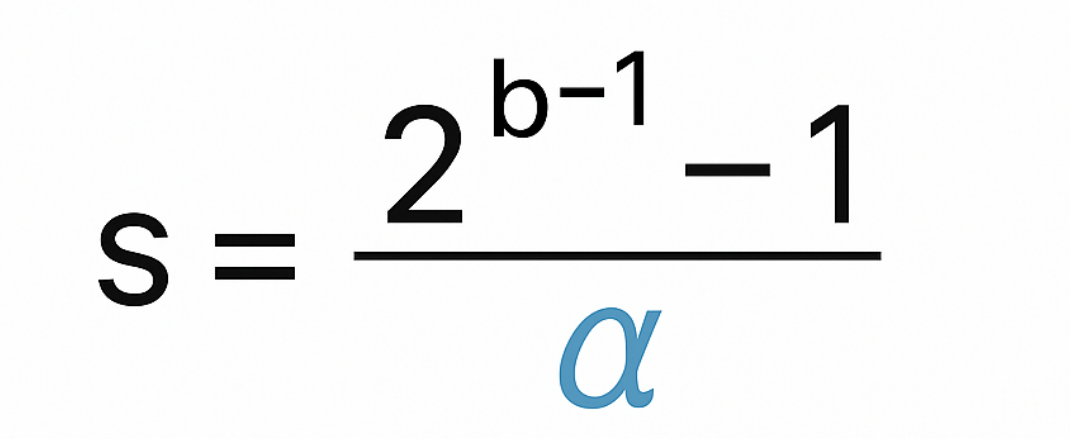
b is the number of bit depth that we want to quantize to (i.e 8 => 2^(8-1) – 1 =127)
α is the highest absolute value (10.8) see figure
Quantized Formula:
A Quantized weight value is equal to the weight times the scaling factor s
X_quantized ≈ round (x * s)DeQuantized Formula:
DeQuantized weight value is equal to the quantized weight divided by the scaling factor s
X_Dequantized ≈ X_quantized / sllama.cpp
The llama.cpp is a C++ library for efficient inference of (LLMs) performing custom quantization approach to compress the models in a GGUF format developed by Georgi Gerganov.
- This reduces the size and resources needed.
- many inference engines (
ollama/vllm) usellama.cppunder the hood to enable on-device LLM llama.cppreads models saved in the.GGMLor.GGUFformat and enables them to run on CPU devices or GPUs.- Serving as a port of meta’s LLaMA model,
llama.cppextends accessibility to a broader audience. - allow
CPU+GPUhybrid inference to accelerate models larger than total VRAM capacity. - Various quantization options (
1.5-bitto8-bitinteger) for faster inference and reduced memory usage. - Support for AVX, AVX2, and AVX512 instructions for x86 architectures.
GGML (Georgi Gerganov ML)
GGML is a C Tensor library designed for deploying (LLMs) on consumer hardware with effective CPU inferencing.
- ggml is similar to ML libraries such as PyTorch and TensorFlow
- Supports various quantization (i.e.,
4-bit,5-bit, and8-bit) to balance efficiency and performance. - GGML offers a Python binding called C Transformers, which simplifies inferencing by providing a high-level API and eliminates boilerplate code.
- Started being considered by organizations exploring self-hosted LLM solutions.
GGML format
Funny things is that GGML is also the file format used to store these quantized models which is a format for distributing LLMs. It contains all necessary information to load a model (tensors, tokenizers, config…).
💡All weights are tensors, but not all tensors are weights…
GGUF (GPT-Generated Unified Format)
GGUF is a file format optimized for faster CPU-based inference or GPU acceleration using libraries like llama.cpp.
It’s the successor to GGML format in 2023.
- GGUF encapsulates all necessary components for inference, including the
tokenizerandcode, within a single file. - Adds support for the conversion of non-Llama models.
- It facilitates model quantization to lower precisions to improve speed & memory efficiency on CPUs.
- Allows new additions to models without breaking compatibility.
- Compatible with future hardware.
GGUF advantages over GGML
- Smarter Tokenization: Supports special tokens & metadata.
- Faster Inference: Optimized quantization for CPUs & optional GPU acceleration.
- Future-Proof: Compatible with new hardware & features.
- Streamlined: All metadata in one file for easier model use & upgrades.
GGUF & llama.cpp:
- Exclusive Format: llama.cpp now only supports GGUF, dropping GGML.
- Optimized Compatibility: GGUF ensures seamless deployment, new features, and hardware optimizations.
Quantization Methods
We often write “GGUF quantization” but GGUF itself is only a file format, not a quantization method.llama.cpp supports multiple quantization techniques and stores the results in GGUF.
Fixed-Point Quantization:
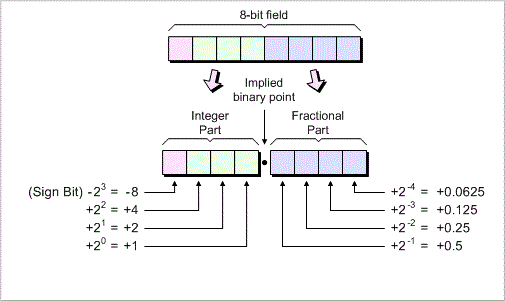
Fixed point Is a quantization where the values are scaled to integers and interpreted as fixed-point numbers.
Efficient for integer-only inference (e.g., in embedded systems).
To represent fractional numbers we can use an implied binary point.
Example: using four bits to represent the integer part of the number and another four bits to represent the fractional part.
Zero Point in Quantization
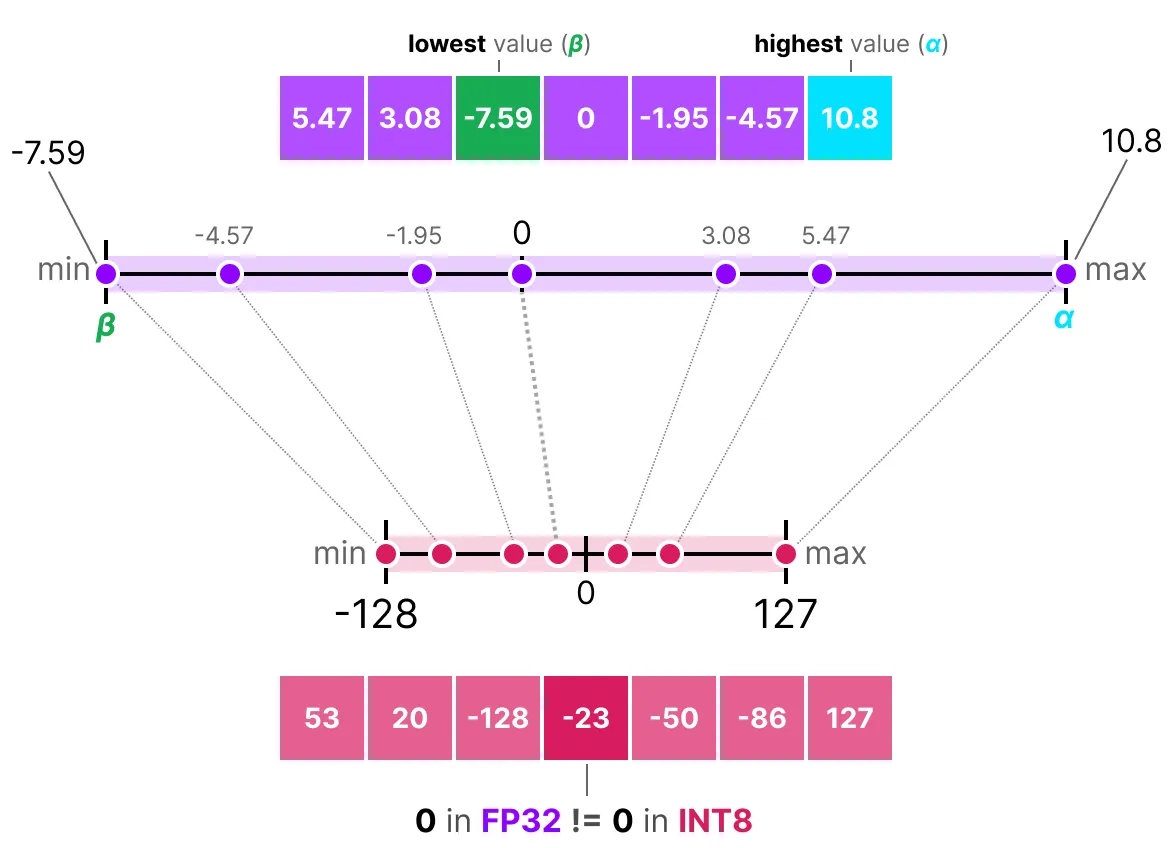
A zero point is a value used in asymmetric quantization to map floating-point numbers into integer values while preserving the range and scale. It allows quantized values to represent both positive and negative numbers using unsigned integers (e.g., INT8).
- Zero point helps shift quantized values so that zero in the FP range aligns with a specific integer (middle of the dynamic range int8
:128). - It maps the minimum (β) and maximum (α) values from the float range to the minimum and maximum values of the quantized range.
- We adjust everything by shifting it with a zero point
Microsoft BitNet Quants (1bit)
The new MSFT Bitnet framework represents each parameter with only 3 values ( -1, 0, and 1) resulting in 1.58 bits.
1-Bit Revolution: Microsoft’s BitNet architecture focuses on 1-bit LLMs, improving efficiency without sacrificing performance.
It has its own library called bitnet.cpp and claims better perf than llama.cpp (x2 to x6 faster).
{kind=link}
Read More here
- Works like llama.cpp, but specialized for 1-bit quantization, training, and inference.
- Combines 1.58-bit weights (-1, 0, 1) and 8-bit activations for lower memory and I/O costs.
- Introduces hybrid quantization + sparsification to reduce computation.
- Dynamically applies techniques based on the distribution of activations. (8-bit precision quantized activations)
- Models are now also supported by llama.cpp since this pull request
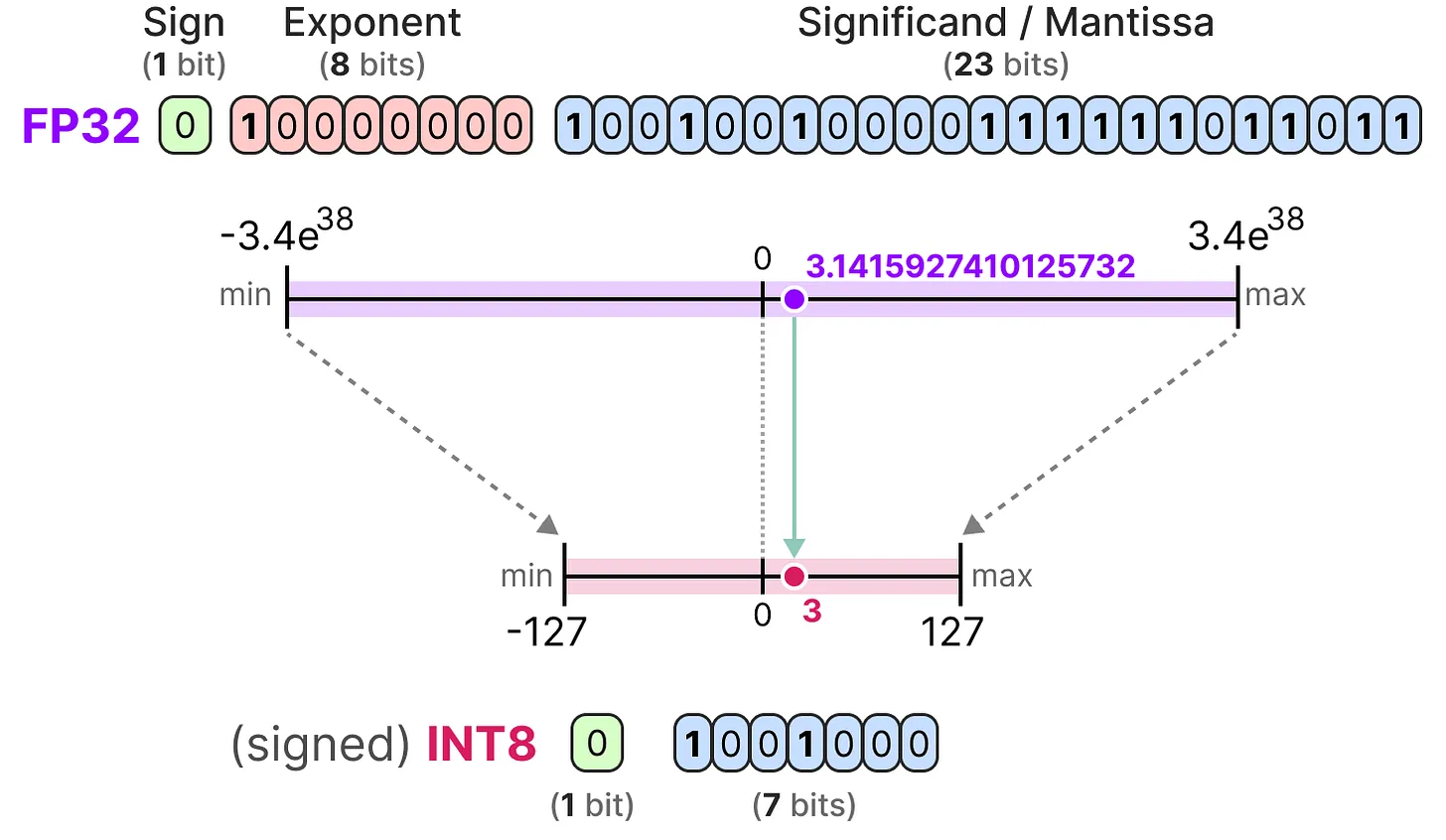
INT8 Quants
Is a model where weights and activations are converted from 32-bit floating point to 8-bit integers that use zero points to represent signed numbers.
❌ not the most popular Quant
- Numbers with negative & positive values might need a shift to center them in 8-bit range (0 to 255 for unsigned, -127 to 127 for signed).
Quantization Formula:
A weight value w is stored as a 8-bit integer q, and its approximation is equal to the weight times the scaling factor s (+ zero point if available)
q=round(W/s +z)
-- example
𝑞 = (−2.5 /0.02 )+ 128 = 0q→ Quantized integer value (e.g., INT8)W→ Original floating-point values→ Scaling factor (determines how much precision is lost)z→ Zero point (integer offset that aligns 0 in floating-point with an integer value)
You can read more here
💡 This ensures weights are mapped efficiently into the 8-bit range while maintaining relative scale.
Blockwise Quants (Q4_0, Q4_1, Q8_0):
Is a basic and fast quantization method where Instead of shrinking the whole model at once, we split it into small blocks (i.e., 16 or 32 weights per block) and apply quantization individually to each block. Read more in this redit post.
This helps keep better precision because each block gets its own rules for shrinking, instead of using one rule for the entire model.
❌ not the most popular Quant
Main difference between Qn_0 and Qn_1
The main difference is the scaling factors dumber between the two types we’ll take Q4 as an example
📌 Q4_0 (4-bit)
- 4 bits per weight
- Only One scaling factor per block (typically 32 weights per block)
- all weights in the block share the same scale
- No per-weight adjustments → lower precision but extreme compression.
- No outlier (bias) scaling factor handling
📌 Q4_1 (4-bit)
- Same block size as Q4_0 (32 weights per block).
- Two scaling factors per block:
- Primary scaling factor (for most values).
- Outlier(bias) scaling factor (to adjust extreme weights).
- More precise than Q4_0 since it corrects for outliers while still keeping compression.
| Format | How it Works | Precision |
|---|---|---|
| Q4_0 | One scale per block | Lower |
| Q4_1 | One scale + outlier adjustment | Higher |
K-Quants (Q3_K_S, Q5_K_M, …)
K-means quant in an optimized quantization method introduced in llama.cpp PR #1684 that improves accuracy and efficiency over older formats.
It offers a range of quantization options & varying levels of precision and efficiency, providing flexibility in model deployment and optimization.
- Adaptive size/accuracy: uses different bit sizes for smarter compression to find your best size/accuracy ratio.
- Better bit allocation: dynamically assign higher weights to higher precision, while the others get lower-bit .
- Block Structure:
Q4_Ksplits in weights superblocks of 8 blocks of 32 weights and result in 4.5 bitperweight.- Each block has 1 scaling factor + extra scaling factor per superblock (for outliers)
- Precision Where It Matters: Key weights get higher precision, others get lower.
✅ The best & most popular Quant in the community 🚀
Quality evaluation
1. Perplexity (ppl)
Perplexity is a crucial metric for evaluating the performance of LLMs in tasks. Intuitively, perplexity means to be surprised. We measure how much the model is surprised by seeing new data.
The lower🔽 the perplexity, the better👍🏻 the training is.
- Perplexity is usually used only to determine how well a model has learned the training set.
- Lower perplexity indicates that the model is more certain about its predictions and vice versa
Perplexity Increase Relative to Unquantized:
| Model | Measure | F16 | Q2_K | Q3_K_M | Q4_K_S | Q5_K_S | Q6_K |
|---|---|---|---|---|---|---|---|
| 7B | perplexity | 5.9066 | 6.7764 | 6.1503 | 6.0215 | 5.9419 | 5.9110 |
| 7B | file size | 13.0G | 2.67G | 3.06G | 3.56G | 4.33G | 5.15G |
| 7B | ms/tok @ 4th, M2 Max | 116 | 56 | 69 | 50 | 70 | 75 |
| 7B | ms/tok @ 8th, M2 Max | 111 | 36 | 36 | 36 | 44 | 51 |
| 7B | ms/tok @ 4th, RTX-4080 | 60 | 15.5 | 17.0 | 15.5 | 16.7 | 18.3 |
| 7B | ms/tok @ 4th, Ryzen | 214 | 57 | 61 | 68 | 81 | 93 |
2. KLD (Kullback-Leibler Divergence)
While perplexity (PPL) is a common metric to measure how surprised a model is by new data, KLD provides a more direct comparison of model faithfulness” to the original weights. How “similarly bad or good” both models are?
- Simplicity: KLD is easy to calculate and gives a concrete number to optimize.
- Noise Reduction: less prone to random noise vs regular benchmarks (MMLU) when comparing different quants.
- Extra effort: requires to run on the original model the save the results then do the same for the quantized mode.
- Limitations: It can have a poor correlation with degradation on hard, long-context problems
- Lower score is better: Indicates a more faithful predictions of the quantized model’s to the original model.
Model Quantization Naming
Quantization methods are denoted by “Q[Number]_K_Size”.
"Q[Number]"represents the bit depth of quantization."K"signifies K-Quants or knowledge distillation."Size"indicates the size of the model, with"S"for small,"M"for medium, and"L"for large.
Recommendations:
k models are k-quant models and generally have less perplexity loss relative to size.
Q4_K_M,Q5_K_S, andQ5_K_Mare considered “recommended” due to their balanced quality and relatively low perplexity increase.Q2_Kshows extreme quality loss and is not recommended.Q3_K_SandQ3_K_Mhave high-quality loss but can be suitable for very small models.K8_0has virtually no quality loss but results in extremely large file sizes and is not recommended.q4_K_Mmodel will have much less perplexity loss than a q4_0 or even a q4_1 model.
GGUF Models on CPU:
On my laptop, my sweet spot is always Q4_K_M or S
- Model parameters: 7B to 13Billions
- Avg size: 4-4.9GB
- Performance: decent token throughput/accuracy on limited resource(no GPU).
User-Friendly Quantization Tools
If you are looking for a user-friendly quantization experience, you can use the following hugging face community spaces and notebooks:
Bitsandbytes Space
GGUF Space
MLX Space
AuoQuant Notebook
Grouped Query Attention GQA
Grouped Query Attention is primarily used during inference, not training.
It simplifies how LLMs understand large amounts of text by bundling similar pieces/queries together into a single operation , optimizing computation/Memory overhead by:
- Optimizes Attention: Reduces redundancy & speeds up attention calculations.
- More Efficient: Processes groups of words instead of each word individually.
- Faster & Lighter: Improves quality while cutting memory & compute costs.
- Used In:
llama.cpp, Hugging Face (custom models), vLLM, LLaMA models. - Benefit
- Quality: Matches multi-head attention (MHA) quality while optimizing efficiency.
- Speed: As fast as multi-query attention (MQA), faster than MHA.
- How? Uses fewer key-value heads to balance speed & accuracy.
Conclusion
If you’ve made it this far—respect. 💪🏻 Quantization is a maze of numbers, scaling tricks, and trade-offs. I hope this page becomes your go-to spot for (re)learning quantization essentials—whether you’re diving in fresh or just need a quick refresher.
Reference
- Quantization guide for LLMs
- The_difference_between_quantization_methods
- llama.cpp
- Overview_of_gguf_quantization_methods
- My_head_is_spinning_with_all_the_quantization
- gguf-quantization-with-imatrix-and-k-quantization-to-run-llms-on-your-cpu
- GPTQ 4bit quantization explanation
- Quantization-fundamentals-with-hugging-face(course)
- Microsoft’s Bitnet: Extreme quantization made easy
- Gguf model perf parser (benchmark calculator)
- GGUF-Model-VRAM-Calculator
- Can I Run this LLM
- A visual guide to quantization

Run AI Your Way — In Your Cloud
Want full control over your AI backend? The CloudThrill VLLM Private Inference POC is still open — but not forever.
📢 Secure your spot (only a few left), 𝗔𝗽𝗽𝗹𝘆 𝗻𝗼𝘄!
Run AI assistants, RAG, or internal models on an AI backend 𝗽𝗿𝗶𝘃𝗮𝘁𝗲𝗹𝘆 𝗶𝗻 𝘆𝗼𝘂𝗿 𝗰𝗹𝗼𝘂𝗱 –
✅ No external APIs
✅ No vendor lock-in
✅ Total data control