Introduction:
The goal of this section is to explore some of the Oracle Clusterware feaures as node fencing, callouts, as well as working with services and Policy managed servers . To know more about the cluster lab used in this article please have a look on my previous RACattack on Redhat 7 blog post >> Deploying Oracle RAC Database 12c Lab on Red Enterprise Linux 7
Content :
- Configure Oracle Client
- Node Fencing
- Clusterware Callouts
- Service Failover
- Policy Managed Database
- Preferred DNS server: 192.178.78.51
- Alternate DNS server: 192.178.78.52
- Check Append these DNS suffixes (in order) option:
- Click Add… and enter evilcorp.com in the Domain suffix field that appears.
- Click Add.
- Click OK and/or Close until you exit from the Network configuration.
- DB access:
- Pluggable DB access:
- Test
- Node fencing Go to Top
- Clusterware callout Go to Top
- expected result: Both members run the clusterware callout script.
- expected result: Only the failed node will run the clusterware callout script.
- Other possible tests : Powering off one of the virtual machines ;disabling a network interface ..etc
- Service Failover Go to Top
To connect from a client outside the cluster Vms (virtualBox) we will need to download and install Oracle’s Basic Instant Client
1. Download Oracle’s Basic (English-only) Instant Client and Oracle’s Instant Client SQLPlus package from Oracle’s website :
(instantclient-basiclite-windows.x64-12*zip and instantclient-sqlplus-windows.x64-12*zip)2. Each archive contains a folder named “instantclient_12_1”. Extract this folder (from both archives) into your drive (I.e C: ).
3. Open Windows Network Settings (Control Panel –> Network and Internet -> Network and Sharing Center ) and select Change adapter settings.
– Double Click on VirtualBox Host-Only Network adaptor
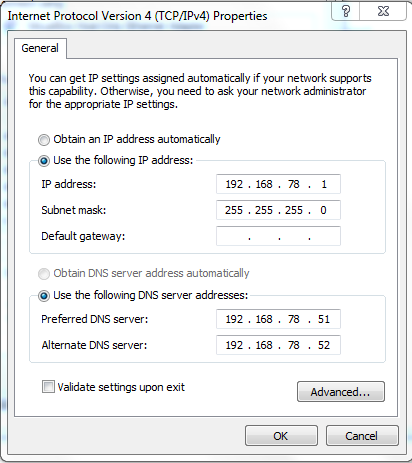
4. Click on Properties then Select Internet Protocol Version 4 (TCP/IPv4) and click Properties
5. Select Use the following DNS server addresses and enter the addresses of the two virtual machines:
6. Click on the Advanced section and select the DNS tab.
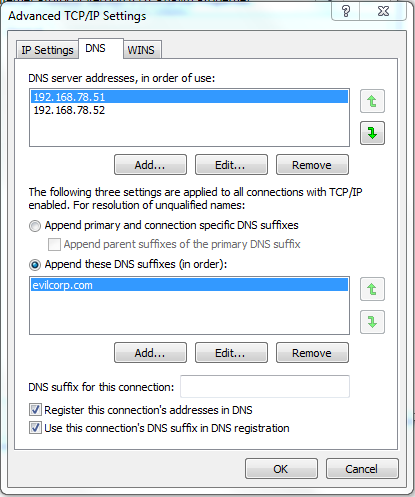
7. Check both Register the connection’s addresses in DNS and Use this connection’s DNS suffix in
DNS registration.
8. Open a Command prompt and check that the DNS resolution is working properly on your laptop:
C:UsersIronman> nslookup - 192.168.78.51 Default Server: london1.evilcorp.com Address: 192.168.78.51 > london-cluster-scan Server: london1.evilcorp.com Address: 192.168.78.51 Name: london-cluster-scan.evilcorp.com Addresses:192.168.78.253 192.168.78.252 192.168.78.2519. Test your Instant Client installation by connecting to the database.
C:instantclient_12_1> sqlplus system/racattack@//london-cluster-scan/RAC_DB.evilcorp.com
SQL*Plus: Release 12.2.0.1.0 Production on Mon Jul 2 18:54:02 2018
Copyright (c) 1982, 2016, Oracle. All rights reserved.
Connected to:
Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production
With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,
Advanced Analytics and Real Application Testing options
SQL> select instance_name from v$instance;
INSTANCE_NAME
----------------
RACDB1
SQL>C:instantclient_12_1> sys/racattack@//london-cluster-scan/RAC_DB.evilcorp.com as sysdba SQL> alter pluggable database PDB open; SQL> alter pluggable database PDB save state; SQL> connect system/racattack@//london-cluster-scan/PDB.evilcorp.com Connected.10. Create a TNSNAMES file and copy the TNS RAC entries from either nodes (PDB entry included) and run a tnsping
C:instantclient_12_1> notepad C:instantclient_12_1tnsnames.ora
RAC =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = london-cluster-scan.evilcorp.com)(PORT = 1521))
(CONNECT_DATA =(SERVER = DEDICATED)
(SERVICE_NAME = RAC_DB.evilcorp.com)) )
PDB =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = london-cluster-scan.evilcorp.com)(PORT = 1521))
(CONNECT_DATA = (SERVER = DEDICATED)
(SERVICE_NAME = PDB.evilcorp.com)))
C:instantclient_12_1> set TNS_ADMIN=c:instantclient_12_1
C:instantclient_12_1> sqlplus system/racattack@RAC
SQL*Plus: Release 12.2.0.1.0 Production on Mon Jul 2 19:51:55 2018
Copyright (c) 1982, 2016, Oracle. All rights reserved.
Last Successful login time: Mon Jul 02 2018 19:18:54 -04:00
Connected to:
Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production
With the Partitioning, Real Application Clusters, Automatic Storage Management,OLAP,Advanced Analytics and Real Application Testing options
SQL> connect system/racattack@PDB
Connected.
Fencing is handled at the node level by rebooting the non-responsive or failed node.
- 1. Monitor the clusterware log files on both nodes. On each node, start a new window and run the following command (log files and their locations have changed in 12.1.0.2)
[grid@<node_name>]$tail –f /u01/app/grid/diag/crs/`hostname -s`/crs/trace/crsd.trc [grid@<node_name>]$tail –f /u01/app/grid/diag/crs/`hostname -s`/crs/trace/ocssd.trc -- Or [grid@<node_name]$ tail –f /u01/app/grid/diag/crs/`hostname -s`/crs/trace/alert.log
2. We will simulate “unplugging” the network interface by taking one of the private network interfaces down. On the london2 node, turn the private network interface down by running the following as root.
[grid@[london2] ifconfig eth1 down
3. We can now start monitoring those log files from step2 and track eventual errors. We will eventually observe that one of the nodes reboots itself.
....... London1 ....... 2018-07-03 00:36:32.665 [OCSSD(2736)]CRS-1610: Network communication with node london2 (2) missing for 90% of timeout interval. Removal of this node from cluster in 2.680 seconds 2018-07-03 00:36:40.122 [OCSSD(2736)]CRS-1625: Node london2, number 2, was shut down 2018-07-03 00:36:40.122 [OCSSD(2736)]CRS-1607: Node london2 is being evicted in cluster incarnation 425999537; 2018-07-03 00:36:50.122 [OCSSD(6016)]CRS-1601: CSSD Reconfiguration complete. Active nodes are london1 .2018-07-03 00:36:51.122 [OCTSSD(8024)]CRS-2407: The new Cluster Time Synchronization Service reference node is host london1. 2018-07-03 00:36:51.2 [CRSD(9680)]CRS-5504: Node down event reported for node 'london2'. 2018-07-03 00:37:10.122 [CRSD(9680)]CRS-2773: Server 'london2' has been removed from pool 'Generic'. 2018-07-03 00:37:10.122 [CRSD(21675)]CRS-2772: Server 'london2' has been assigned to pool 'ora.RAC_DB'. 2018-07-03 00:37:40.122 [OCSSD(6016)]CRS-1601: CSSD Reconfiguration complete. Active nodes are london1 london2 . 2018-07-03 00:38:40.122 [CRSD(9680)]CRS-2772: Server 'london2' has been assigned to pool 'Generic'. ......... london2 - after node reboot ......... [grid@london2 ~]$ nmcli dev status Unknown parameter: eth0 DEVICE TYPE STATE CONNECTION ------- -------- ----------- ----------- eth0 ethernet connected eth0 eth1 ethernet connected eth1 eth2 ethernet connected eth2
[grid@london2 ~]$ srvctl status database -d rac_db
Instance RACDB1 is not running on node london1
Instance RACDB2 is running on node london2
[grid@london1 ~]$ srvctl status nodeapps VIP london1-vip.evilcorp.com is running on node: london1 VIP london2-vip.evilcorp.com is running on node: london2 Network is running on node: london1 Network is running on node: london2 ONS daemon is running on node: london1 ONS daemon is running on node: london2
Description: This feature is a capability for Oracle Clusterware to fire a script (or a whole directory full of them) to perform any sort of tasks required when a cluster-wide event happens (for example database is up, down, or unresponsive).
For this exercise, we will configure few FAN callout scripts on each node and then generate various cluster events to see how each member triggers the callout script.
1. On an up and running cluster open a shell prompt (as oracle) on each node, navigate to $GRID_HOME/racg/usrco. Create our callout script called london_callout.sh using vi .
The content should look like this:#!/bin/ksh umask 022 FAN_LOGFILE=/tmp/`hostname`_uptime.log echo $* "reported="`date` >> $FAN_LOGFILE &2. Make sure permissions on the file are set to 755 using the following command
[oracle@<node_name>]$ chmod 755 /u01/grid/oracle/product/12.1.0.2/grid/racg/usrco/london_callout.sh3. Monitor the log files for clusterware on each node. On each node, start a new window and run the following command:
[oracle@<node_name>]$ tail –f /u01/app/grid/diag/crs/`hostname -s`/crs/trace/alert.log [root@london2 ~]# crsctl stop crs CRS-2791: Starting shutdown of Oracle High Availability Services-managed resources on 'london2' CRS-2673: Attempting to stop 'ora.crsd' on 'london2' CRS-2790: Starting shutdown of Cluster Ready Services-managed resources on 'london2' CRS-2673: Attempting to stop 'ora.rac.db' on 'london2' CRS-2673: Attempting to stop 'ora.DATA.SHARED.advm' on 'london2' CRS-2673: Attempting to stop 'ora.LISTENER.lsnr' on 'london2' ... CRS-2793: Shutdown of Oracle High Availability Services-managed resources on 'london2' has completed CRS-4133: Oracle High Availability Services has been stopped4. Next, we need to trigger an event that will cause the callout to fire. One such event is node shutdown.
Shutdown the clusterware on node london2.
5. Following the shutdown, watch the log files you began monitoring in step 1 above. Because we set long timeouts on our test cluster, you might have to wait for a few minutes before you see anything.
You should see these messages in the /tmp/*.log files indicating that the node is down:
NODE VERSION=1.0 host=london2 status=nodedown reason=public_nw_down incarn=0 timestamp=2018-07-08 16:21:40 timezone=-04:00 vip_ips=192.168.78.62 reported=Sun Jul 8 16:21:40 EDT 2018 INSTANCE VERSION=1.0 service=rac_db.evilcorp.com database=rac_db instance=RACDB2 host=london2 status=down reason=USER timestamp=2018-07-08 16:21:41 timezone=-04:00 db_domain=evilcorp.com reported=Sun Jul 8 16:21:40 EDT 2018Note: I also had the database service shut down on london1 then back up but I suspect it’s due to memory resource starvation on my vms
NODE VERSION=1.0 host=london2 status=nodedown reason=member_leave incarn=426435207 timestamp=2018-07-08 16:38:13 timezone=-04:00 reported=Sun Jul 8 16:38:15 EDT 2018 NODE VERSION=1.0 host=london2 incarn=426435207 status=down reason=member_leave timestamp=08-Jul-2018 16:38:13 reported=Sun Jul 8 16:38:15 EDT 20186. Restart the clusterware.
[root@london2 bin]# crsctl start crs
[root@london2 usrco]# cat /tmp/`hostname`_uptime.logs INSTANCE VERSION=1.0 service=rac_db.evilcorp.com database=rac_db instance=RACDB2 host=london2 status=up reason=BOOT timestamp=2018-07-08 17:35:16 timezone=-04:00 db_domain=evilcorp.com reported=Sun Jul 8 17:35:17 EDT 20187. Let’s trigger another event which is an unexpected database instance shut down. Only the node london2 will run the callout script.
[oracle@london2 ~]$ sqlplus "/ as sysdba" Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.1.0 - 64bit Production SQL> shutdown abort; -[grid@london2 ~]$ cat /tmp/`hostname`_uptime.log INSTANCE VERSION=1.0 service=rac_db.evilcorp.com database=rac_db instance=RACDB2 host=london2 status=down reason=USER timestamp=2018-07-08 17:55:37 timezone=-04:00 db_domain=evilcorp.com reported=Sun Jul 8 17:55:37 EDT 2018
1. Login to london1 as the oracle user. Create a new service svctest with RACDB1 as a preferred instance and RACDB2 as an available instance. This means that it will normally run on the RACDB1 instance but will failover to the RACDB2 instance if RACDB1 becomes unavailable.
If you haven’t created a container database, omit the -pdb parameter.
[oracle@london1]$ srvctl add service -d RAC_DB -pdb PDB -s svctest -r RACDB1 -a RACDB2 -P BASIC [oracle@london1]$ srvctl start service -d RAC_DB -s svctest2. Examine where the service is running by checking lsnrctl on both nodes and looking at the SERVICE_NAMES init parameter on both nodes.
[oracle@london1]$ srvctl status service -d RAC_DB -s svctest Service svctest is running on instance(s) RACDB1 [oracle@london1]$ lsnrctl services ... Service "svctest.evilcorp.com" has 1 instance(s). Instance "RACDB1", status READY, has 1 handler(s) for this service... Handler(s): "DEDICATED" established:1 refused:0 state:ready LOCAL SERVER[oracle@london2]$ lsnrctl services ---- svctest not found in the listSQL> select name, pdb, inst_id from gv$services; NAME PDB INST_ID ---------------------------------- ------------------------------ --------- svctest PDB 1 RAC_DB.evilcorp.com CDB$ROOT 1 pdb.evilcorp.com PDB 1 pdb.evilcorp.com PDB 2 RAC_DB.evilcorp.com CDB$ROOT 23. Use SHUTDOWN ABORT to kill the instance where service svctest is running.
SQL> Show user USER is "SYS" SQL> select instance_name from v$instance; INSTANCE_NAME ---------------- RACDB1 SQL> shutdown abort; ORACLE instance shut down. SQL>4. Wait a few moments and then repeat step 2. The service stops running.
[oracle@london1]$ srvctl status service -d RAC_DB -s svctest Service svctest is not running.5. Restart the instance that you killed.
[oracle@london1]$ srvctl status database -d RAC_DB Instance RACDB1 is not running on node london1 Instance RACDB2 is running on node london2 [oracle@london1]$ srvctl start instance -d RAC_DB -i RACDB1 [oracle@london1]$ srvctl status database -d RAC_DB Instance RACDB1 is running on node london1 Instance RACDB2 is running on node london26. Repeat step 2. the service is now running back in RACDB1
[oracle@london1]$ srvctl status service -d RAC_DB -s svctest Service svctest is running on instance(s) RACDB17. Manually failover the service. Confirm where it is now running. Note that this does not disconnect any current sessions
[oracle@london1]$ srvctl relocate service -d RAC_DB -s svctest -i RACDB2 -t RACDB1 [oracle@london1]$ srvctl status service -d RAC_DB -s svctest Service svctest is running on instance(s) RACDB1
- Policy managed database Go to Top
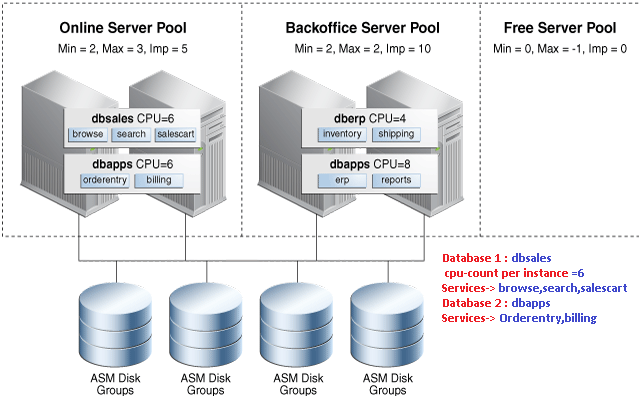
Overview: Two deployment models exist for designing Oracle RAC and Oracle RAC One Node databases:
- Administrator-managed : Only available model up to Oracle 11.2. It requires static configuration of database instance to run on a specific node, as well as a database services to run on specific instances belonging to a certain database using the
preferredandavailabledesignation.- Administrator-managed: Relies on server pools, where database services run within a server pool as singleton(active on only one instance in the server pool) or uniform(active on all instances in the server pool) across all of the servers in the server pool.
Serverpools:
are logical partitions of a larger physical cluster composed of groups of servers (Server Pool). Each pool have three main properties: IMPORTANCE (0-1000), MIN_SIZE(default 0), MAX_SIZE(-1 cluster-wide) .
Note: I wish I had more nodes in my cluster to provide a more exhaustive preview of the feature, alas my laptop memory is already agonizing. Thus my examples will rely on a 2 node cluster.
1. First let’s Create and Manage a new Server Pool using either crsctl or srvctl
# crsctl add serverpool srvpl01 -attr MIN_SIZE=0 ,MAX_SIZE=2, IMPORTANCE=0 SERVERNAMES=london1 london2— OR
# srvctl add srvpool -serverpool srvpl01 -min 1 -max 4 -servers london1,london22. Assign the RAC_DB Database to our new serverpool
- Stop the database # srvctl stop database -d RAC_DB - Modify and assign it to a serverpool # srvctl modify database -d RAC_DB -serverpool srvpl01 - Restart the database for the modification to take effect # srvctl start database -d RAC_DB3. Verify our new configuration
- Check the configuration of the newly created serverpool # srvctl config serverpool -serverpool srvpl01 Server pool name: srvpl01 Importance: 0, Min: 0, Max: 4 Category: Candidate server names: london1,london2 # crsctl status serverpool ora.srvpl01 -f NAME=ora.srvpl01 IMPORTANCE=0 MIN_SIZE=0 MAX_SIZE=4 SERVER_NAMES=london1 london2 PARENT_POOLS= EXCLUSIVE_POOLS= ACL=owner:grid:rwx,pgrp:oinstall:rwx,other::r-- SERVER_CATEGORY= ACTIVE_SERVERS=london1 london2- verify the association of the database to the serverpool [root@london2 ~]# srvctl config database -db RAC_DB Database unique name: RAC_DB Database name: RAC_DB Oracle home: /u01/app/oracle/product/12.1.0.2/db_1 Oracle user: oracle Spfile: +DATA/RAC_DB/PARAMETERFILE/spfile.275.975538943 Password file: +DATA/RAC_DB/PASSWORD/pwdrac_db.284.975537953 Domain: evilcorp.com Start options: open Stop options: immediate Database role: PRIMARY Management policy: AUTOMATIC Server pools: srvpl01 Disk Groups: FRA,DATA Mount point paths: Services: svctest Type: RAC ... Database is policy managedPost conversion changes :
– Instances name will slightly change after switching to policy management. The inst numbers are preceded with an underscore (racdb1=>racdb_1) which will require you to change the TNS entries accordingly.
If the passwordfile is stored in a file system you’ll have to change its name as well# mv orapwdDBNAME1 orapwDBNAME_1– OEM: If Database was registered with OEM cloud 12c. Change existing instances name with new ones (racdb_1)
Summary and Advantages of policy managed Databases :– Resources defined in advance to cope with workload needs
– Breaks explicit association between services,instances, and nodes
– Sufficient instances are automatically started to satisfy the service to serverpool association defined by the cardinality (uniform and singleton) instead of the usual admin managed options ( preferred / available)Further examples: The below figure is yet another use case where policy managed databases happen to share two server pools having different priorities allowing consolidation and CPU caging.
If you want to learn more about it you can check out the excellent post from Ludovico Caldara