
Intro
Every generation from an LLM is shaped by parameters under the hood. Knowing how to tune is important so that you can produce sharp and more controlled outputs. Here are the 7 levers that matter most.
Make sure to try the interactive playground at the bottom to visualize and play with each parameter.
1) Max tokens

- Absolute limit on total generated tokens in a single response.
- Too low → truncated outputs; too high → could lead to wasted compute and generation time
2) Temperature
Controls output randomness by manipulating probability scores.

- Low temperature (~0) forces precision and repetition;.
- Higher temperature (0.7–1.0) boosts creativity, diversity, and increase hallucination risk.
- Use case: lower for QA/chatbots, higher for brainstorming/creative tasks.
3) Top-k
The default way to generate the next token is to sample from all tokens, proportional to their probability.
k represents the size of the filtered pool, which can be as large as the model’s entire vocabulary_size (its dictionary).

- This parameter restricts the sampling pool to the top
kmost probable tokens, using a practical range of 1 to 100.- Deterministic (k=1): for tasks requiring absolute precision
- Balanced (k=20–40): for general chat and news articles.
- Creative: (k=50–100): for creative writing etc
- Example: k=10 → The model ignores all options outside the top 10 candidates.
- Helps enforce focus, but overly small k (k=1) limits diversity and risks repetitive loops.
4) Top-p (nucleus sampling)
Dynamically selects the smallest set of tokens whose cumulative probability exceeds p.

- Instead of picking from all tokens or top k tokens, model samples from a probability mass up to p.
- Example: top_p=0.9 → only top choices that make up 90% of the distribution are considered.
- More adaptive than top_k, useful when balancing coherence with diversity in the answers.
5) Frequency penalty

- Reduces the likelihood of reusing tokens based on how often they already appeared.
- Positive values discourage repetition, negative values exaggerate it.
- Useful for summarization (avoid redundancy) to avoid stale language.
6) Presence penalty
Encourages novelty by penalizing tokens that have appeared at least once.

- Encourages the model to bring in new tokens not yet seen in the text.
- Higher values push for novelty, lower values make the model stick to known patterns.
- Handy for exploratory brainstorming or where diversity of ideas is valued.
7) Stop sequences

- Custom list of tokens that immediately halt generation (up to 4 strings).
- Critical in structured outputs (e.g., stopping after a closing
}in JSON)., preventing spillover text. - Enforces hard output boundaries more reliably than prompt instructions alone.
Bonus: ⚙️ Min-P sampling
is a dynamic truncation method that adjusts the sampling threshold based on the model’s confidence at each decoding step. Unlike top-P, which uses a fixed cumulative probability threshold, min-P looks at the probability of the most likely token and only keeps tokens that are at least a certain fraction (the min-P value) as likely.
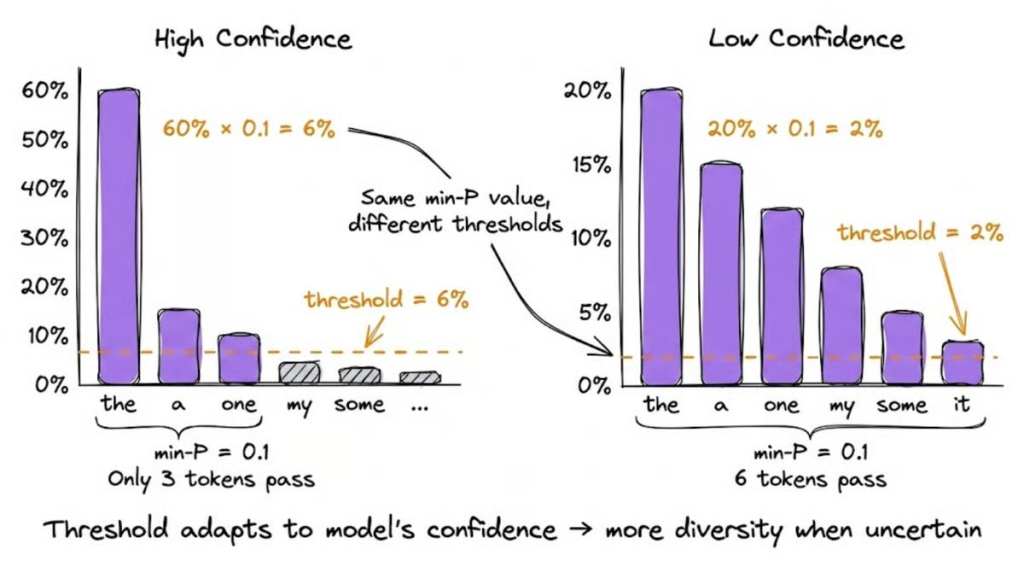
So if your top token has 60% probability and min-P is set to 0.1, only tokens with at least 6% probability make the cut. But if the top token is just 20% confident, then the adapted 2% threshold lets many more candidates through.
This dynamic behavior automatically tightens or loosens the sampling pool depending on model confidence, achieving coherence when the model is certain and diversity when it’s genuinely uncertain.
Experiments show that min-P sampling improves both quality and diversity across different model families and sizes. Human evaluations also indicate a clear preference for min-P outputs in both text quality and creativity.
Setting the base threshold between
0.05 and 0.1 typically balances creativity and coherence well across most tasks.
Playground (TL;DR)
Instead of just reading about how these parameters work, you can use the interactive widget below to experiment with the three most critical dials: Temperature, Top-K, and Top-P.
LLM Output Simulator
Adjust the parameters to see how they filter the model’s choices.
Final Sampling Pool
The model is considering all available tokens based on their baseline probability.
Conclusion
There is no "one-size-fits-all" configuration for LLM generation parameters. The secret to getting the best out of any model is matching your parameter setup to your specific use case. If you need rigid JSON or exact code, drop your temperature and utilize stop sequences. If you are building a creative writing assistant, lean into higher temperatures, top-p, and play around with frequency penalties. Tweak, test, and tune until the output matches your vision!
Hope this helps next time you deploy a model and need to tune these parameters on an inference platform !

Run AI Your Way — In Your Cloud
Want full control over your AI backend? The CloudThrill VLLM Private Inference POC is still open — but not forever.
📢 Secure your spot (only a few left), 𝗔𝗽𝗽𝗹𝘆 𝗻𝗼𝘄!
Run AI assistants, RAG, or internal models on an AI backend 𝗽𝗿𝗶𝘃𝗮𝘁𝗲𝗹𝘆 𝗶𝗻 𝘆𝗼𝘂𝗿 𝗰𝗹𝗼𝘂𝗱 -
✅ No external APIs
✅ No vendor lock-in
✅ Total data control
𝗬𝗼𝘂𝗿 𝗶𝗻𝗳𝗿𝗮. 𝗬𝗼𝘂𝗿 𝗺𝗼𝗱𝗲𝗹𝘀. 𝗬𝗼𝘂𝗿 𝗿𝘂𝗹𝗲𝘀...
🙋🏻♀️If you like this content please subscribe to our blog newsletter ❤️.