
intro
Even after Oracle AutoUpgrade, many times in 3 different OS’. Yet the more you think you’ve seen it all and reached the highest confidence level, another Upgrade will come byte you in the butt. The truth is every maintenance in any software or platform is unique, Oracle databases are no exception. Automation will not solve all your problems which means organizations will still need humans when things get nasty.
We hope the fixes will help you save precious time during your production upgrades. Enjoy
AutoUpgrade is still the best
Despite some issues, AutoUpgrade remains the best option to upgrade databases to 19c before the final leap to 23ai and it’s easy to agree, after checking the below methods available to upgrade/migrate to 19c in this migration white paper.
The environment
In my case, I needed to migrate my 12c CDB to 19c, while preserving the Data Guard setup & reducing downtime.
| Platform | Source CDB database SI | Target CDB SI | Grid /ASM | Dataguard |
|---|---|---|---|---|
| Linux RHEL 8 | 8 12.1.0.2 Enterprise Edition | 19.17.0.0 Enterprise Edition |  | |
AutoUpgrade
| 19c jdk | autoupgrade.jar |
| 1.8.0_201 | Build.version 22.4.220712 |
The Upgrade strategy
While the upgrade process itself isn’t covered here, I’ll mention the steps required to reproduce our AutoUpgrade in a Data Guard protected environment. If you want to look further into the steps, check out the excellent article by Daniel Overby Hansen called How to Upgrade with AutoUpgrade and Data Guard.
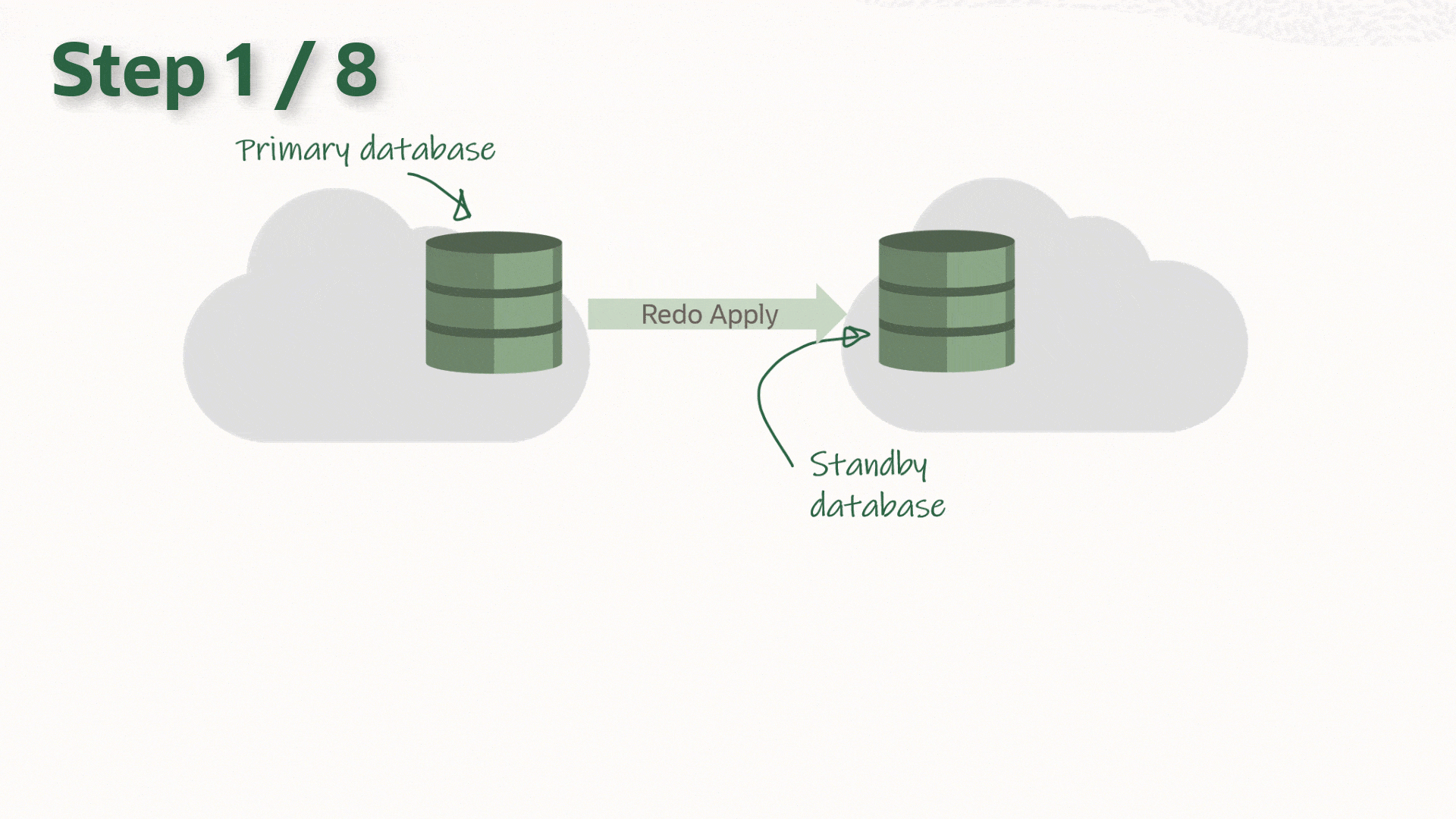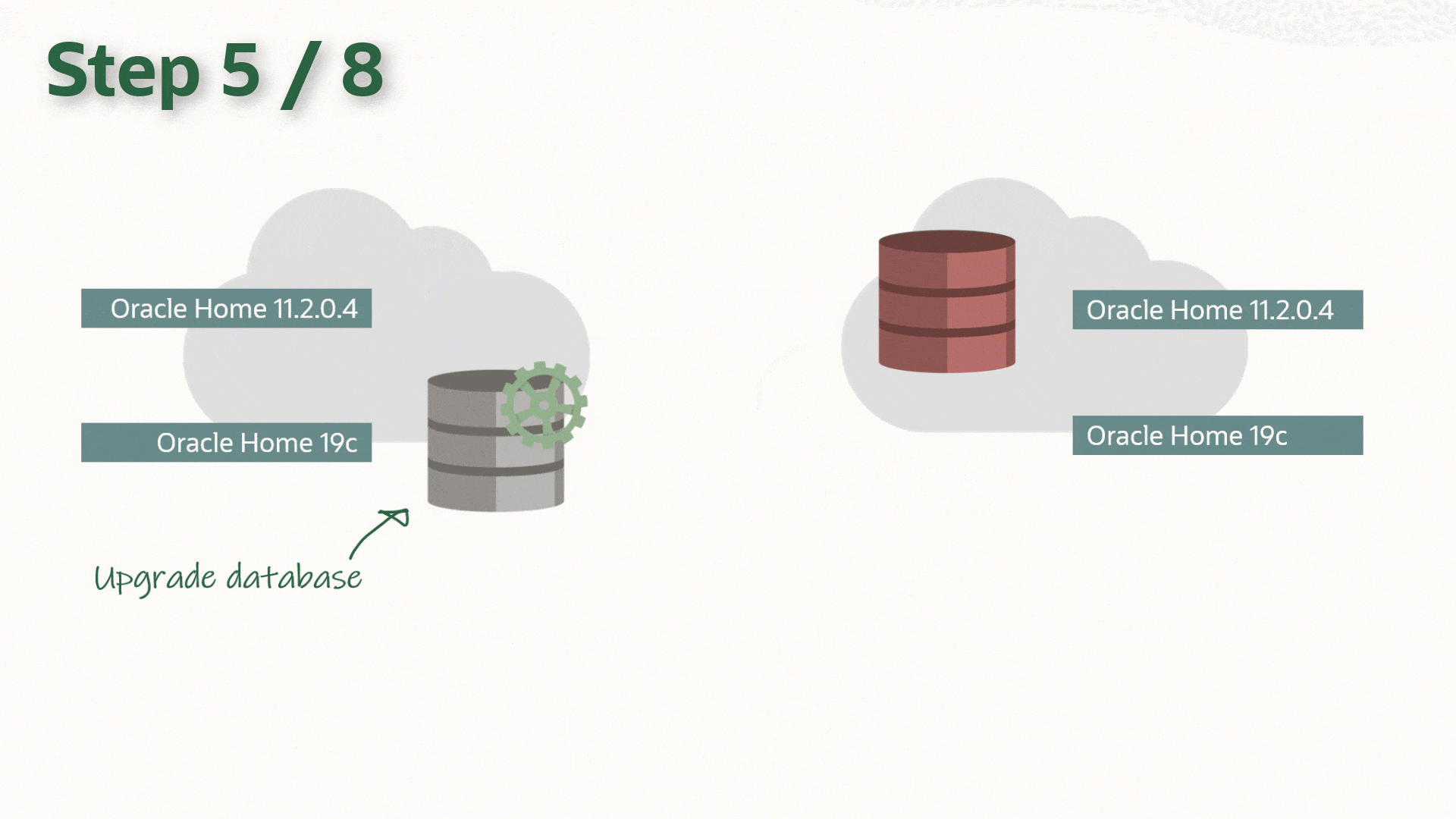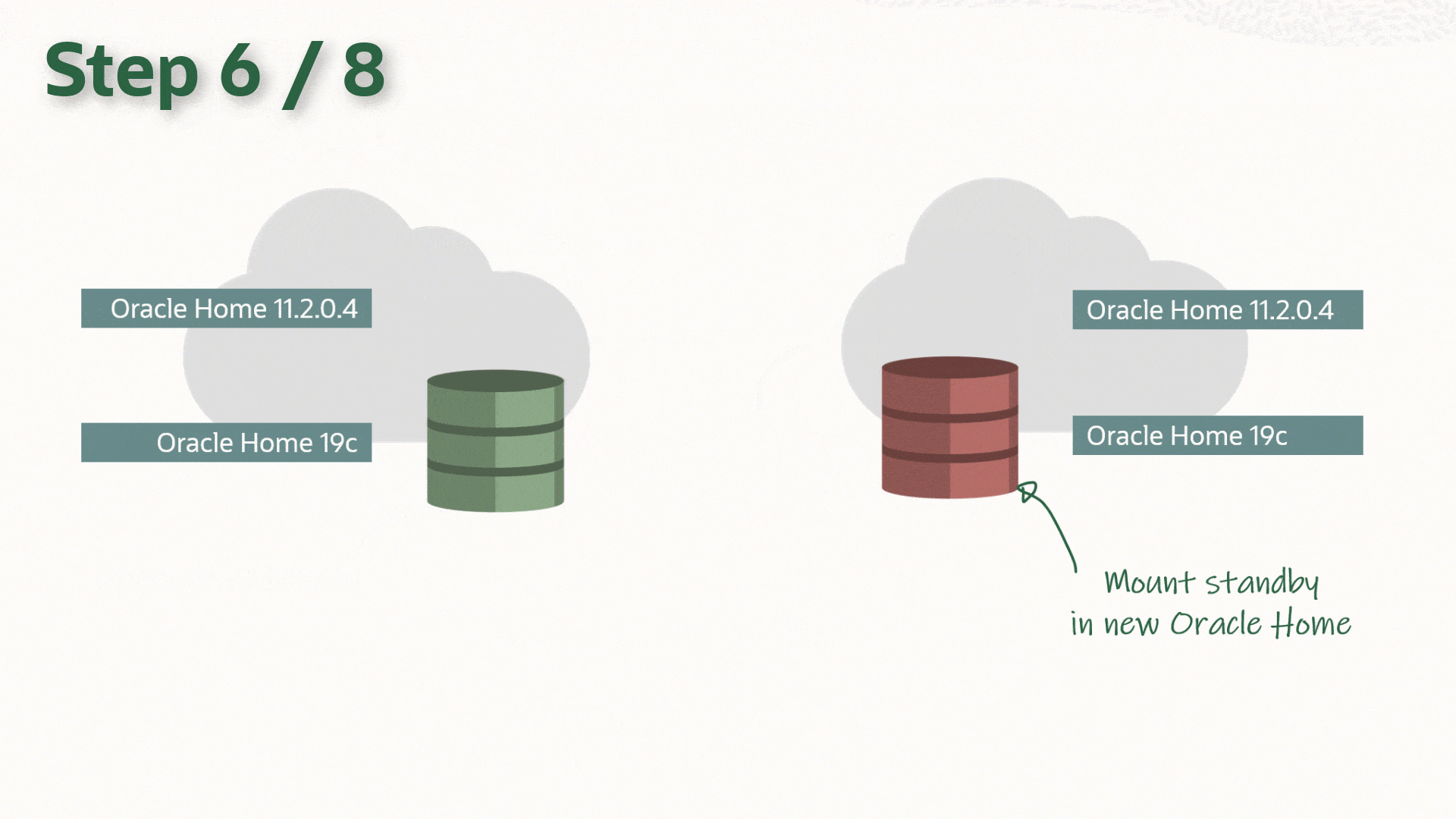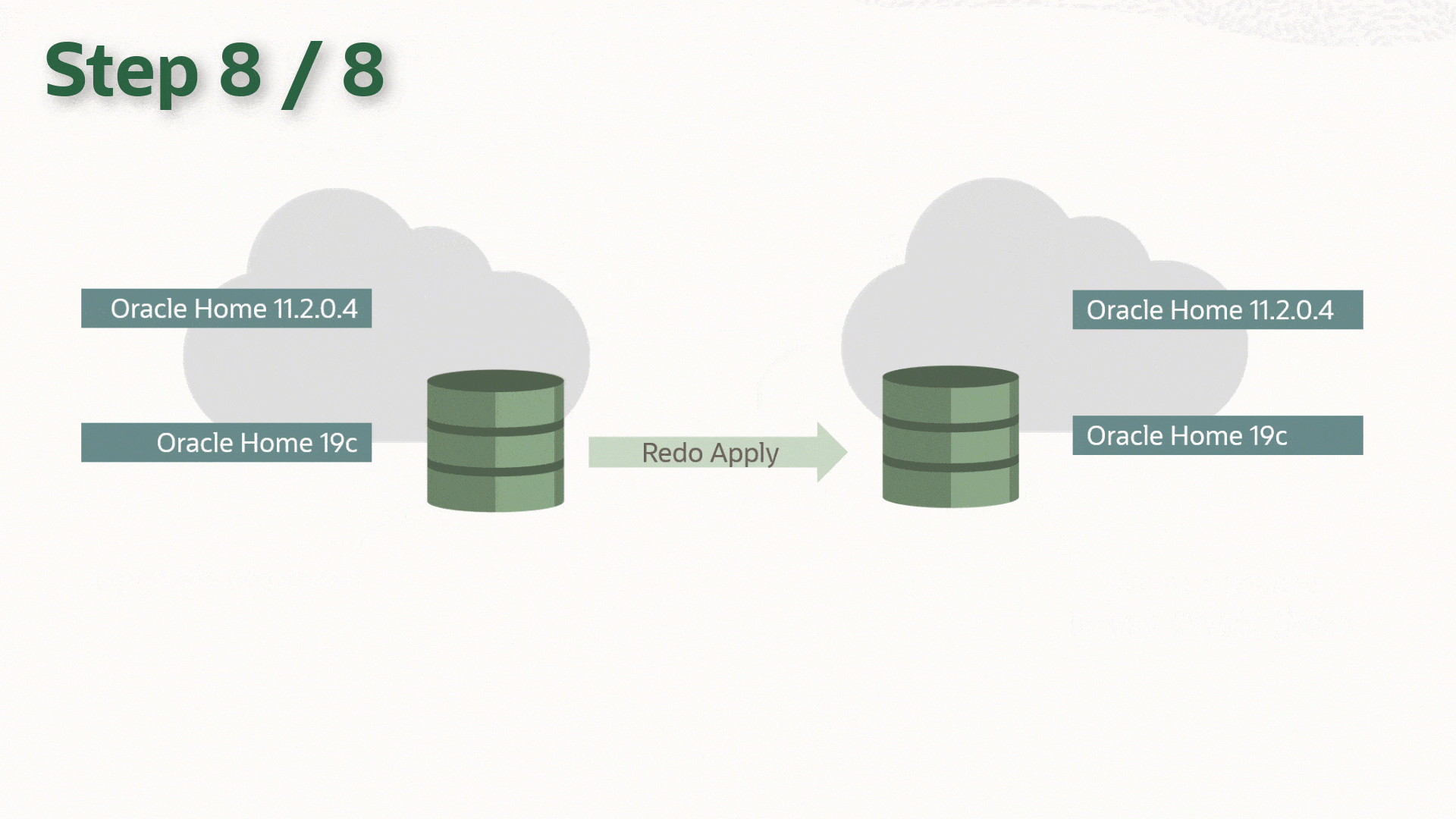
The following is assumed to be already completed on both primary and standby hosts:
- Install and patch a new 19c Oracle Database Home to the latest RU
- Installing and patching a new 19c grid infrastructure to the latest RU
- Upgrading the existing 12c grid into the new one (19c)
The steps
- Stop Standby Database
- Upgrade the primary DB
- Run AutoUpgrade with the appropriate Config file [analyze, fixups, deploy]
After Upgrade
- Restart Data Guard
- Update the listener and /etc/oratab on the standby host.
- Upgrade the DB by updating the Oracle Home information (srvctl upgrade database)
- Re-enable Data Guard
- Update RMAN catalog to new 19c client’s version
Reproduce the issue
The configuration
After running AutoUpgrade Analyze to clear all warnings from the prechecks. The deploy unfortunately crashed.
# Global configurations
global.autoupg_log_dir=/u01/install/Autoupgrade/UPG_logs
###################
Database number 1 #
###################
upgd1.sid=CDBPROD
upgd1.source_home=/u01/app/oracle/product/12.2.0.1/dbhome_1
upgd1.target_home=/u01/app/oracle/product/19.0.0/dbhome_1
upg1.log_dir=/u01/install/Autoupgrade/UPG_logs/PROD
upg1.run_utlrp=yes
upg1.source_tns_admin_dir=/u01/app/oracle/product/12.2.0.1/dbhome_1/network/admin
upg1.timezone_upg=yes
upg1.restoration=yes1. Autoupgrade analyze
C:\> java -jar autoupgrade.jar -config UP19_PROD.cfg -mode analyze2. Autoupgrade deploy
The environment was ready for a go so I launched the deploy phase
C:\> java -jar autoupgrade.jar -config UP19_PROD.cfg -mode deploy
... An hour later
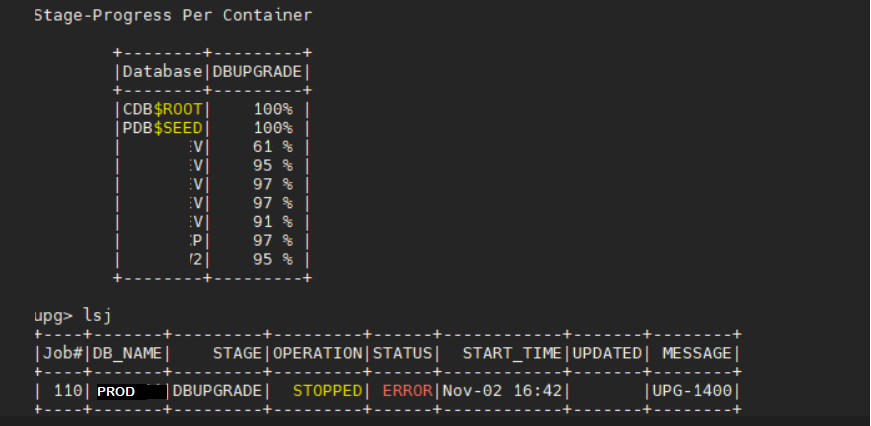
upg> lsj
+----+-------+---------+---------+-------+--------------+--------+------------+
|Job#|DB_NAME| STAGE |OPERATION| STATUS| START_TIME | UPDATED| MESSAGE |
+----+-------+---------+---------+-------+--------------+--------+------------+
| 107| PROD |DBUPGRADE|STOPPED | ERROR | Nov 02 16:42 | |UPG-1400 |
+----+-------+---------+---------+-------+--------------+--------+------------+
upg>
----------------------------------------------
Errors in database [PROD-MYPDB1] Stage [DBUPGRADE]
Operation [STOPPED] Status [ERROR]
Info [ Error: UPG-1400 UPGRADE FAILED [PROD-MYPDB1]
Cause: Database upgrade failed with errors ORA-03113JAVA SYSTEM Error
The upgrade of CDB$ROOT and PDB$SEED went fine, but all remaining PDBs failed at phase 53 of the upgrade.
This is just an example for one of the error received by most of the PDBs in the source 12c CDB
DATABASE NAME: PROD-MYPDB1
CAUSE: ERROR at Line 831816 in
[/u01/install/Autoupgrade/UPG_logs/PROD/107/dbupgrade/catupgrdyyy-mmdd-MYPDB0.log]
REASON: ORA-03113: end-of-file on communication channel
ACTION: [MANUAL]
DETAILS: 03113, 00000, "end-of-file on communication channel"
// *Cause: The connection between Client and Server process was broken.
...
- CheckForErrors.checkForErrors When I check the line described in the error in catupgrd log file we can see the below excerpt at Line 831816.
Elapsed: 00:00:00.65
11:32:14 SQL>
11:32:14 SQL> -- Load all the Java classes
11:32:14 SQL> begin if initjvmaux.startstep('CREATE_JAVA_SYSTEM') then
11:32:14 2 initjvmaux.rollbacksetup;
11:32:14 3 commit;
11:32:14 4 initjvmaux.rollbackset;
11:32:14 5 initjvmaux.exec('create or replace java system');
11:32:14 6 commit;
11:32:14 7 initjvmaux.rollbackcleanup;
11:32:14 8 initjvmaux.endstep;
11:32:14 9 dbms_registry.update_schema_list('JAVAVM',
11:32:14 10 dbms_registry.schema_list_t('OJVMSYS'));
11:32:14 11 end if; end;
11:32:14 12 /
begin if initjvmaux.startstep('CREATE_JAVA_SYSTEM') then <------------- JAVA ERROR
*
ERROR at line 1:
ORA-03113: end-of-file on communication channel
ERROR: ORA-03114: not connected to ORACLEExplanation
Root cause
This is due to java sys objects corruption that often happen for those who had a non-CDB not having Long Identifiers (either before 12.2.0.1 or COMPATIBLE was below 12.2.0), plugged it into a CDB having Long Identifiers (default since 12.2.0.1 as soon as COMPATIBLE is 12.2.0 or higher).
In other words phase 53 had two script that was supposed to recreate java sys objects that were already corrupt. see Note (MOS Note: 2691097.1)
[phase 53] type is 1 with 2 Files
@cmpupjav.sql @cmpupnjv.sql in these cases, you have a sleeping corruption which may not cause trouble. Unless you upgrade this PDB to a newer release causing the above error.
How to verify if the corruption exist
there is an easy script to query if there are any of these objects that are still corrupt as shown below
---- JAVA CORRUPTION CHECK:
sys@Prod.Mypdb1> select count(*) from obj$ where bitand(flags, 65600)=64 and type# in (29,30);
COUNT(*)
----------
26725 <---- will cause upgrade failure
Solution
We’ll have to manually cleanup all those corrupt sys objects before resuming the upgrade as described in MOS Note: 2691097.1
I have gathered all the sequenced commands in a script on my git repo called fix_java_corruption.sql
vi fix_java_corruption.sql
col name new_val pdb_name noprint
select name from v$pdbs;
spool &pdb_name._java_fix.log
set feed on
alter session set "_ORACLE_SCRIPT"=true;
prompt -- 1. create rootobj view
create or replace view rootobj sharing=object as select obj#,o.name,u.name
uname,o.type#,o.flags from obj$ o,user$ u where owner#=user#;
prompt -- 2. update flags on #obj view where type# in (28,29,30,56)
update obj$ set flags=flags+65536 where type# in (28,29,30,56) and
bitand(flags,65536)=0 and obj# in (select o.obj# from obj$ o,user$ u,rootobj
r where o.name=r.name and o.type#=r.type# and o.owner#=u.user# and
u.name=r.uname and bitand(r.flags,65536)!=0 union select obj# from obj$ where
bitand(flags,4259840)=4194304);
prompt -- 3. update flags on #obj view where bitand(flags,65600)=64 (not always present)
update obj$ set flags=flags+65536
where bitand(flags,65600)=64 and
obj# in (select o.obj# from obj$ o,x$joxft x
where x.joxftobn=o.obj# and
bitand(o.flags,65600)=64 and
bitand(x.joxftflags,64)=64);
prompt -- 4. delete objects from idl_ubl view
delete from sys.idl_ub1$ where SYS_CONTEXT('USERENV','CON_ID')>1 and
obj# in (select obj# from sys.obj$ where
bitand(flags, 65536)=65536 and type# in (28,29,30,56));
prompt -- commit
commit;
spool offExecution
do the following for each PDB
------ Repeat for all PDBs
1. ALTER SESSION SET CONTAINER=<PDBNAME>;
SQL> fix_java_corruption.sql
...
-- 1. create rootobj view
View created.
-- 2. update flags on #obj view where type# in (28,29,30,56)
28293 rows updated.
-- 3. update flags on #obj view where bitand(flags,65600)=64 (not always present)
0 rows updated.
-- 4. delete objects from idl_ubl view
28447 rows deleted.
-- commit
Commit complete.Check if corruption is gone
@check_java_corruption
COUNT(*)
----------
0Resume the job
once the fix is applied to each faulty PDB you can resume the Auto upgrade
upg> resume -job 107After this the Autoupgrade completed successfully and the standby database was re-enabled as expected in the remaining steps.
Conclusion
- While automation tools like AutoUpgrade are powerful, they can’t predict and fix all potential bottlenecks.
- Staying vigilant and utilizing troubleshooting skills remains crucial especially when the downtime window is tight
- These ara yet again error that the prechecks could not spot for you which could have been life saver during late production maintenances.
Thanks for reading